ORC Text Snap
Extract text from images with Optical Character Recognition
ما هو ORC Text Snap؟
ORC Text Snap هو إضافة Chrome تم تطويرها بواسطة Jofen، والميزة الرئيسية لها هي "Extract text from images with Optical Character Recognition".
لقطات شاشة التمديد



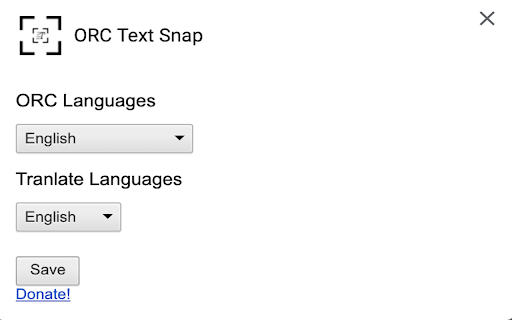
تحميل ملف CRX للإضافة ORC Text Snap
قم بتنزيل ملفات الامتداد ORC Text Snap بتنسيق crx ، وقم بتثبيت الامتدادات يدويًا في متصفح Chrome ، أو شارك ملفات crx مع الأصدقاء لتثبيت الامتدادات بسهولة.
تعليمات استخدام التمديد
Optical Character Recognition - Copy text from any image, video or PDF
===========
A handy tool to extract text from images, videos or PDF with just one click and crop instead of retyping the text character by character. A tipical use case is to copy any text from youtube videos, image formatted tutorials.
This tool copies text from images using the lightweight OCR engine [Tesseract.js](https://github.com/naptha/tesseract.js).
How to use it:
1. Click the icon, then select the area/image containing the text.
2. Wait until the tool to extract the text for you.
3. Extracted result will show in a text box. You can then click the copy button to load it into your Clipboard and Ctrl + V to paste it anywhere.
4. There is an option to translate the extracted text into your selected language.
5. You can define the ORC language and targeted translation languages on the options page. معلومات أساسية عن التمديد
| الاسم |  ORC Text Snap ORC Text Snap |
| ID | cjcbfnbbhjipgbbncobdgdpphnlalife |
| عنوان URL الرسمي | https://chromewebstore.google.com/detail/orc-text-snap/cjcbfnbbhjipgbbncobdgdpphnlalife |
| الوصف | Extract text from images with Optical Character Recognition |
| حجم الملف | 236 KB |
| عدد التثبيتات | 1,886 |
| النسخة الحالية | 1.1 |
| آخر تحديث | 2022-09-17 |
| تاريخ النشر | 2019-08-27 |
| تقييم | 2.00/5 مجموع تقييمات 5 |
| المطور | Jofen |
| البريد الإلكتروني | [email protected] |
| نوع الدفع | free |
| اللغات المدعومة | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"name": "ORC Text Snap",
"description": "Extract text from images with Optical Character Recognition",
"version": "1.1",
"manifest_version": 2,
"background": {
"scripts": [
"dist\/main.js",
"js\/background.js"
],
"persistent": false
},
"browser_action": {
"default_icon": {
"19": "images\/icon19.png",
"38": "images\/icon38.png"
},
"default_title": "Extract text from images"
},
"options_ui": {
"page": "html\/options.html",
"open_in_tab": false,
"chrome_style": true
},
"icons": {
"16": "images\/icon16.png",
"48": "images\/icon48.png",
"128": "images\/icon128.png"
},
"homepage_url": "https:\/\/github.com\/jofen-chrome-extensions\/orc-text-snap",
"web_accessible_resources": [
"html\/iframe\/*",
"images\/Jcrop.gif",
"images\/pixel.png",
"images\/close.png"
],
"commands": {
"take-screenshot": {
"suggested_key": {
"default": "Alt+S"
},
"description": "Take Screenshot"
}
},
"permissions": [
"storage",
"tabs",
"activeTab",
"clipboardWrite"
],
"content_scripts": [
{
"matches": [
"*:\/\/*\/*"
],
"js": [
"vendor\/jquery.js",
"js\/inject.js"
],
"css": [
"css\/inject.css"
],
"run_at": "document_start"
}
],
"content_security_policy": "script-src 'self' 'unsafe-eval' https:\/\/cdn.jsdelivr.net; object-src 'self'"
} | |











