Image Reader (OCR)
Easily get words out of an image with OCR engine!
Co je Image Reader (OCR)?
Image Reader (OCR) je rozšíření Chrome vyvinuté Sevina, a jeho hlavní funkcí je „Easily get words out of an image with OCR engine!“.
Snímky obrazovky rozšíření
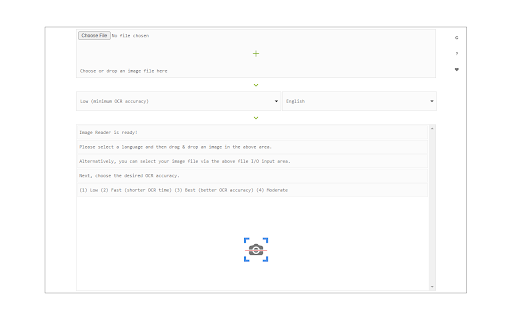

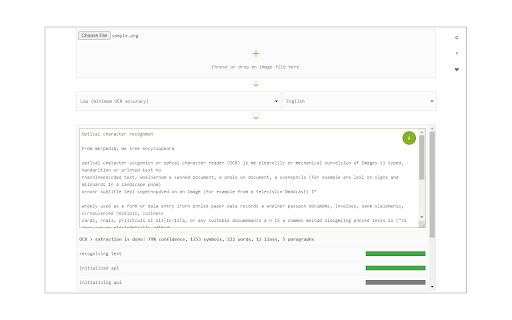
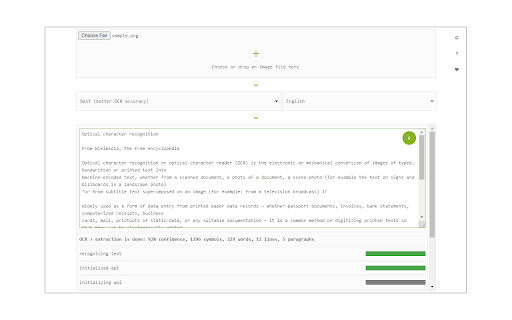
Stáhnout soubor CRX rozšíření Image Reader (OCR)
Stáhněte si soubory rozšíření Image Reader (OCR) ve formátu crx, ručně nainstalujte rozšíření Chrome do prohlížeče nebo sdílejte soubory crx s přáteli, abyste jednoduše nainstalovali rozšíření Chrome.
Pokyny pro Použití Rozšíření
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info.
To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English.
Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package.
To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html). Základní Informace o Rozšíření
| Název |  Image Reader (OCR) Image Reader (OCR) |
| ID | cakcfocedphbadddjpalejbkhflfbhmf |
| Oficiální URL | https://chromewebstore.google.com/detail/image-reader-ocr/cakcfocedphbadddjpalejbkhflfbhmf |
| Popis | Easily get words out of an image with OCR engine! |
| Velikost souboru | 7.51 MB |
| Počet instalací | 31,444 |
| Aktuální Verze | 0.1.7 |
| Poslední Aktualizace | 2023-12-07 |
| Datum Vydání | 2019-08-27 |
| Hodnocení | 3.85/5 Celkem 20 Hodnocení |
| Vývojář | Sevina |
| [email protected] | |
| Typ Platby | free |
| Webové stránky Rozšíření | https://mybrowseraddon.com/image-reader.html |
| URL Stránky Nápovědy | https://mybrowseraddon.com/image-reader.html |
| URL Stránky Zásad Ochrany Soukromí | https://mybrowseraddon.com/privacy-policy/developer/sevina.html |
| Podporované Jazyky | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"version": "0.1.7",
"manifest_version": 3,
"offline_enabled": true,
"name": "Image Reader (OCR)",
"permissions": [
"storage",
"contextMenus"
],
"homepage_url": "https:\/\/mybrowseraddon.com\/image-reader.html",
"description": "Easily get words out of an image with OCR engine!",
"commands": {
"_execute_action": []
},
"background": {
"service_worker": "background.js"
},
"content_security_policy": {
"extension_pages": "script-src 'self' 'wasm-unsafe-eval'; object-src 'self'"
},
"action": {
"default_title": "Image Reader (OCR)",
"default_icon": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png"
}
},
"icons": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png",
"128": "data\/icons\/128.png"
}
} | |











