Image Reader (OCR)
Easily get words out of an image with OCR engine!
Was ist Image Reader (OCR)?
Image Reader (OCR) ist eine Chrome-Erweiterung, die von Sevina entwickelt wurde, und ihr Hauptmerkmal ist "Easily get words out of an image with OCR engine!".
Erweiterungsscreenshots
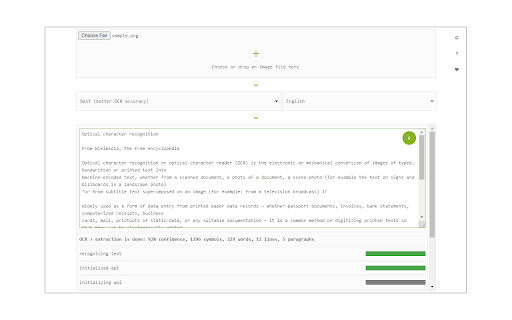
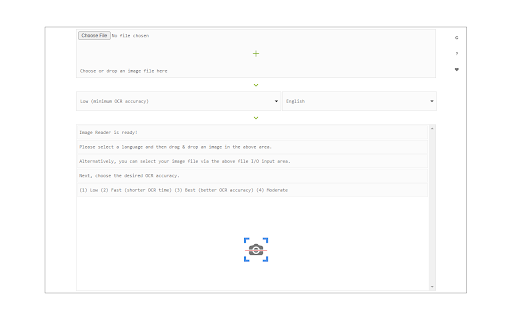

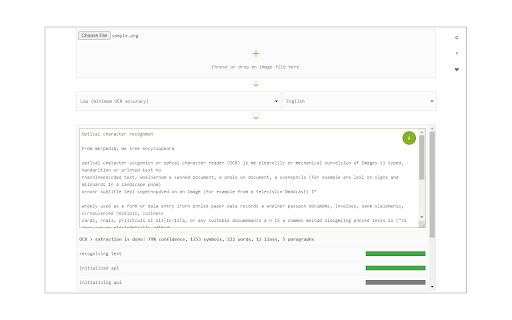
Image Reader (OCR)-Erweiterungs-CRX-Datei herunterladen
Laden Sie Image Reader (OCR)-Erweiterungsdateien im crx-Format herunter, installieren Sie Chrome-Erweiterungen manuell im Browser oder teilen Sie die crx-Dateien mit Freunden, um Chrome-Erweiterungen einfach zu installieren.
Anleitung zur Verwendung der Erweiterung
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info. To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English. Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package. To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html).
Grundlegende Informationen zur Erweiterung
| Name |  Image Reader (OCR) Image Reader (OCR) |
| ID | cakcfocedphbadddjpalejbkhflfbhmf |
| Offizielle URL | https://chromewebstore.google.com/detail/image-reader-ocr/cakcfocedphbadddjpalejbkhflfbhmf |
| Beschreibung | Easily get words out of an image with OCR engine! |
| Dateigröße | 7.51 MB |
| Installationsanzahl | 31,444 |
| Aktuelle Version | 0.1.7 |
| Letztes Update | 2023-12-07 |
| Veröffentlichungsdatum | 2019-08-27 |
| Bewertung | 3.85/5 Insgesamt 20 Bewertungen |
| Entwickler | Sevina |
| sevina.lucia@gmail.com | |
| Zahlungsart | free |
| Erweiterungswebsite | https://mybrowseraddon.com/image-reader.html |
| Hilfeseite URL | https://mybrowseraddon.com/image-reader.html |
| URL der Datenschutzrichtlinien-Seite | https://mybrowseraddon.com/privacy-policy/developer/sevina.html |
| Unterstützte Sprachen | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"version": "0.1.7",
"manifest_version": 3,
"offline_enabled": true,
"name": "Image Reader (OCR)",
"permissions": [
"storage",
"contextMenus"
],
"homepage_url": "https:\/\/mybrowseraddon.com\/image-reader.html",
"description": "Easily get words out of an image with OCR engine!",
"commands": {
"_execute_action": []
},
"background": {
"service_worker": "background.js"
},
"content_security_policy": {
"extension_pages": "script-src 'self' 'wasm-unsafe-eval'; object-src 'self'"
},
"action": {
"default_title": "Image Reader (OCR)",
"default_icon": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png"
}
},
"icons": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png",
"128": "data\/icons\/128.png"
}
} | |











