Internet Archive Downloader
Download PDF books from archive.org
Was ist Internet Archive Downloader?
Internet Archive Downloader ist eine Chrome-Erweiterung, die von Element Davv entwickelt wurde, und ihr Hauptmerkmal ist "Download PDF books from archive.org".
Erweiterungsscreenshots

Internet Archive Downloader-Erweiterungs-CRX-Datei herunterladen
Laden Sie Internet Archive Downloader-Erweiterungsdateien im crx-Format herunter, installieren Sie Chrome-Erweiterungen manuell im Browser oder teilen Sie die crx-Dateien mit Freunden, um Chrome-Erweiterungen einfach zu installieren.
Anleitung zur Verwendung der Erweiterung
Internet Archive(archive.org) holds more than 34 millions books for free access. Some mean to be read online by borrowing for a limit period. This extension can download these books for later reading.
HathiTrust Digital Library(hathitrust.org) support added. All books with full view permission can be downloaded at a click.
Usage
For Internet Archive(https://archive.org/):
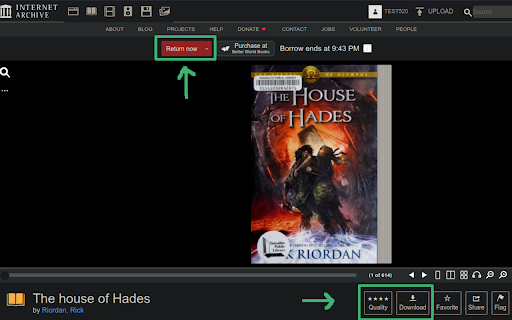
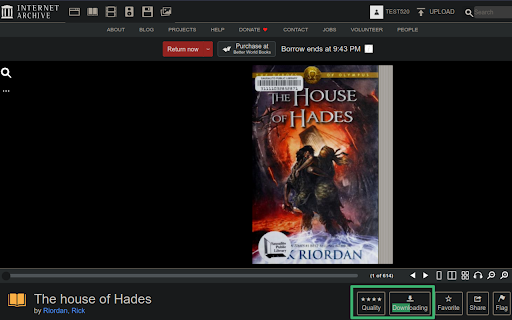
After borrowing a book, two new buttons named "Quality" and "Download" will appear under the book viewer, beside the "Favorite" button.
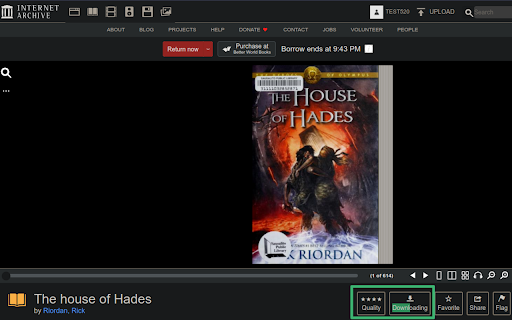
To get current book as PDF file, click the "Download" button.
To get each leaf as a JPEG file, click the "Download" button with Ctrl key pressed(Command key on Mac).
With the download begins, the button will turn into a progress bar.
There are variant leaf qualities for each book which the extension keeps up to four levels. Click the stars on the "Quality" button to choose one. Default is the best quality(the original image, without scaled down).
For HathiTrust(https://hathitrust.org/):
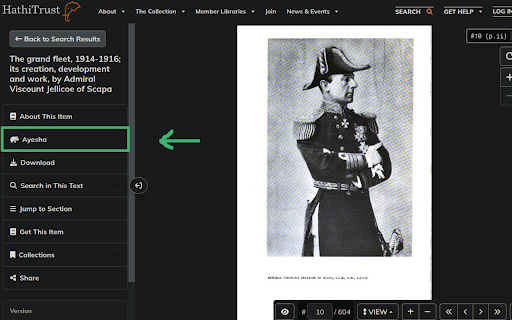
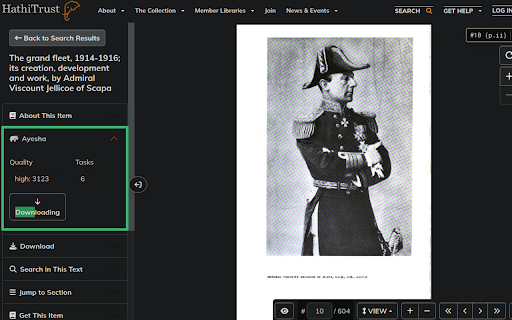
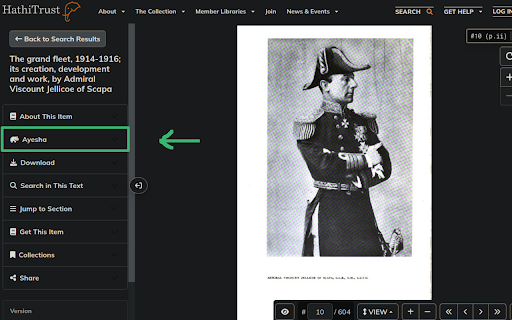
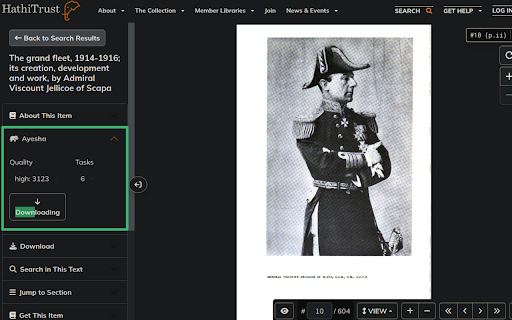
No login, no borrows required. Once a book page loaded, a new section named "Ayesha" will appears above the "Download" section on the left-hand side of the page. Click it to show the download controlls. There are three items, named "Quality", "Tasks" and "Download".
To get current book as PDF file, click the "Download" button.
To get each leaf as a image file(JPEG and/or PNG), click the "Download" button with Ctrl key pressed(Command key on Mac).
With the download begins, the button will turn into a progress bar.
As for leaf quality controll "Quality", the first option is "full size", which will download every page in their highest size, but they may be much different between each others. Other options will download all pages in almost the same size.
The third controll is "Tasks", by which task number running synchronously can be selected. HathiTrust server does not allowed frequent access. The extension have to take some breaks during the download process. Choose a suitable task number to get the best experience.
Availability
For Brave to work properly, item 'File System Access API' in 'brave://flags' page should be enabled.
Change log
v0.7.0
Add hathitrust.org support.
Add png page type support.
Add Http 502/504 gateway errors support, when that happened download will retry, not just abort.
If the download button does not appear due to slow network, you can show it manually by clicking the extension icon on browser toolbar after the page being loaded.
v0.6.3
Possible download succeeded with 0 byte pdf for large file. Now fixed
v0.6.2
* Books will be returned automatically on successful download to make it available to other users
v0.6.1
* Possibble leaf lost caused by unexpected abort. Now fixed
* In some browsers under incorrect settings, download succeeded but no file found. Now fixed
v0.6.0
* Downloads will now retry automatically whenever network errors occured. So it will work more smoothly than ever
* Download process can be aborted immediately now. There is no need to wait for cleaning up any more
* Fix button title place inaccurate
* More browsers are supported
* Compatibility improvements
v0.5.0
* Add option of downloading as JPEG files
v0.4.0
* Retrieve page info from book structure instead of from book reading window, in case it may be incorrect on boundary conditions
* Buttons show up quickly even on slow network now
* Improve the reliability and stability
v0.3.0
* Add option of page quality
* Constraint the download function to media type of books borrowed, don't interfere with other media or books of always available
* Clean uncompleted files on failed/canceled downloads
v0.2.0
* Download to a whole PDF book
* Independant of CORS extension
v0.1.0
* Download each page to a single JPEG file
* Dependant on CORS extension Grundlegende Informationen zur Erweiterung
| Name |  Internet Archive Downloader Internet Archive Downloader |
| ID | keimonnoakgkpnifppoomfdlkadghkjb |
| Offizielle URL | https://chromewebstore.google.com/detail/internet-archive-download/keimonnoakgkpnifppoomfdlkadghkjb |
| Beschreibung | Download PDF books from archive.org |
| Dateigröße | 57.08 KB |
| Installationsanzahl | 33,698 |
| Aktuelle Version | 0.7.0 |
| Letztes Update | 2024-02-25 |
| Veröffentlichungsdatum | 2023-03-08 |
| Bewertung | 4.58/5 Insgesamt 143 Bewertungen |
| Entwickler | Element Davv |
| [email protected] | |
| Zahlungsart | free |
| Erweiterungswebsite | https://github.com/elementdavv/internet_archive_downloader |
| Hilfeseite URL | https://github.com/elementdavv/internet_archive_downloader/issues |
| Unterstützte Sprachen | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"manifest_version": 3,
"author": "Element Davv | |











