ISBN Extractor
Automatically extract all ISBN from a webpage.
Τι είναι το ISBN Extractor;
Το ISBN Extractor είναι ένα πρόσθετο Chrome που αναπτύχθηκε από τον Ray, και η κύρια λειτουργία του είναι "Automatically extract all ISBN from a webpage.".
Στιγμιότυπα Επέκτασης
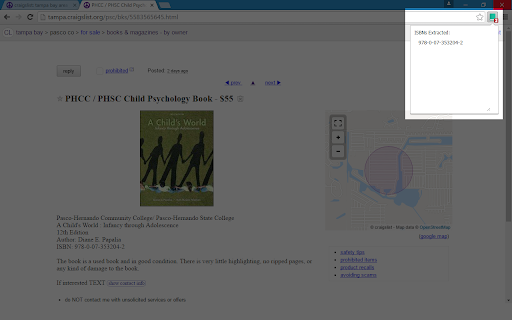
Λήψη αρχείου CRX της επέκτασης ISBN Extractor
Λήψη αρχείων επέκτασης ISBN Extractor σε μορφή crx, εγκατάσταση των επεκτάσεων Chrome μη αυτόματα στον περιηγητή ή κοινοποίηση των αρχείων crx με φίλους για εύκολη εγκατάσταση των επεκτάσεων Chrome.
Οδηγίες Χρήσης της Επέκτασης
This is a simple extension that will extract all ISBN from any web page. Extracts all 10 or 13 digit ISBNs (even if separated by spaces or -). If you want to make the list comma separated or anything like that I recommend http://sortmylist.com/ **Update Version 1.1 ** Updated ISBN matching pattern. ISBN scraping now is a bit cleaner Updated to latest Google APIs Fixed problem of not extracting after switching tabs
Βασικές Πληροφορίες Επέκτασης
| Όνομα |  ISBN Extractor ISBN Extractor |
| ID | bjillcfelggegochlahahhlfcgfmddip |
| Επίσημο URL | https://chromewebstore.google.com/detail/isbn-extractor/bjillcfelggegochlahahhlfcgfmddip |
| Περιγραφή | Automatically extract all ISBN from a webpage. |
| Μέγεθος Αρχείου | 535 KB |
| Αριθμός Εγκαταστάσεων | 479 |
| Τρέχουσα Έκδοση | 1.1.2 |
| Τελευταία Ενημέρωση | 2022-04-23 |
| Ημερομηνία Δημοσίευσης | 2016-06-21 |
| Αξιολόγηση | 4.75/5 Συνολικά 4 Αξιολογήσεις |
| Προγραμματιστής | Ray |
| Ηλεκτρονικό ταχυδρομείο | 2c6az985r@mozmail.com |
| Τύπος Πληρωμής | free |
| Υποστηριζόμενες Γλώσσες | en-US |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"manifest_version": 2,
"name": "ISBN Extractor",
"offline_enabled": true,
"permissions": [
"webNavigation",
"chrome:\/\/favicon\/",
"https:\/\/*\/*",
"http:\/\/*\/*",
"tabs",
"storage"
],
"version": "1.1.2",
"content_security_policy": "script-src 'self' https:\/\/ssl.google-analytics.com; object-src 'self'",
"background": {
"scripts": [
"js\/background.js"
],
"persistent": true
},
"browser_action": {
"default_icon": "icons\/icon512.png",
"default_title": "ISBN Extractor!",
"default_popup": "src\/page_action\/page_action.html"
},
"content_scripts": [
{
"js": [
"js\/content.js"
],
"matches": [
"http:\/\/*\/*",
"https:\/\/*\/*",
"file:\/\/*"
],
"run_at": "document_end"
}
],
"description": "Automatically extract all ISBN from a webpage.",
"icons": {
"512": "icons\/icon512.png"
}
} | |











