Crawler
This extension could be used to crawl all images of a website
Τι είναι το Crawler;
Το Crawler είναι ένα πρόσθετο Chrome που αναπτύχθηκε από τον Dollar, και η κύρια λειτουργία του είναι "This extension could be used to crawl all images of a website".
Στιγμιότυπα Επέκτασης

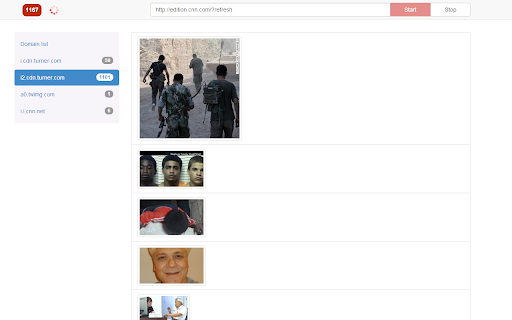


Λήψη αρχείου CRX της επέκτασης Crawler
Λήψη αρχείων επέκτασης Crawler σε μορφή crx, εγκατάσταση των επεκτάσεων Chrome μη αυτόματα στον περιηγητή ή κοινοποίηση των αρχείων crx με φίλους για εύκολη εγκατάσταση των επεκτάσεων Chrome.
Οδηγίες Χρήσης της Επέκτασης
This extension could be used to browse all images of a website recursively.
As technical limitation, we can't automatically download all images into your local file system. So we choose to provide a good UI for these images within browser. In its future version, we will add functions to export data into other formats.
Version 1.1 change list:
1. category the images we got by its domain
2. add URL input box so that user can change crawl site in the manager page.
3. performance enhancement --> use lazy loading so that the image will load only when you scroll to it. Βασικές Πληροφορίες Επέκτασης
| Όνομα |  Crawler Crawler |
| ID | pdhedahnmicgeobhejclpbogemgkfpdo |
| Επίσημο URL | https://chromewebstore.google.com/detail/crawler/pdhedahnmicgeobhejclpbogemgkfpdo |
| Περιγραφή | This extension could be used to crawl all images of a website |
| Μέγεθος Αρχείου | 235 KB |
| Αριθμός Εγκαταστάσεων | 1,820 |
| Τρέχουσα Έκδοση | 1.4 |
| Τελευταία Ενημέρωση | 2014-01-14 |
| Ημερομηνία Δημοσίευσης | 2014-01-13 |
| Αξιολόγηση | 3.17/5 Συνολικά 12 Αξιολογήσεις |
| Προγραμματιστής | Dollar |
| Τύπος Πληρωμής | free |
| Υποστηριζόμενες Γλώσσες | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"background": {
"page": "extension_page\/background.html"
},
"browser_action": {
"default_icon": "icon19.png",
"default_popup": "extension_page\/popup.html"
},
"description": "This extension could be used to crawl all images of a website",
"icons": {
"128": "icon128.png",
"16": "icon16.png",
"48": "icon48.png"
},
"manifest_version": 2,
"name": "Crawler",
"permissions": [
"tabs",
"http:\/\/*\/*",
"https:\/\/*\/*"
],
"content_security_policy": "script-src 'self' https:\/\/ssl.google-analytics.com; object-src 'self'",
"version": "1.4"
} | |











