Documate OCR
Documate OCR
Τι είναι το Documate OCR;
Το Documate OCR είναι ένα πρόσθετο Chrome που αναπτύχθηκε από τον inswanmarket, και η κύρια λειτουργία του είναι "Documate OCR".
Στιγμιότυπα Επέκτασης


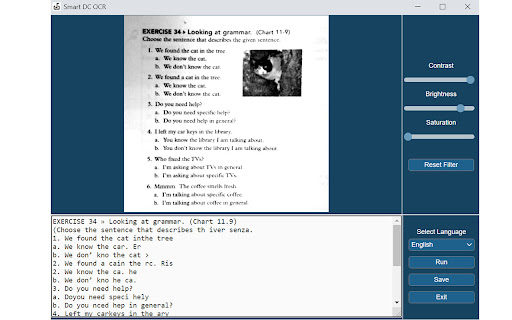
Λήψη αρχείου CRX της επέκτασης Documate OCR
Λήψη αρχείων επέκτασης Documate OCR σε μορφή crx, εγκατάσταση των επεκτάσεων Chrome μη αυτόματα στον περιηγητή ή κοινοποίηση των αρχείων crx με φίλους για εύκολη εγκατάσταση των επεκτάσεων Chrome.
Οδηγίες Χρήσης της Επέκτασης
Documate includes optical character recognition (OCR) functionality to directly extract editable text from scans (JPG, PNG) made with your INSWAN document camera.
How to scan a document in Documate:
1. Connect your INSWAN document camera to your Chromebook using the USB cable.
2. Open the “Documate” software.
3. Capture document images.
4. Go to “Gallery mode” and double click the thumbnail of the captured image.
5. When the thumbnail image is expanded to full screen, click the “Keystone correction” tool to select the area to be scanned and start to correct image distortion.
6. Click on “Save to gallery ” to confirm and save the scanned file as PDF, JPG, PNG, of TIFF.
7. Click the “OCR” icon to extract editable text from the scan.
8. Click on “Return to gallery mode” to return to the thumbnail preview mode to review all captured images.
How to extract text in Documate:
Method 1: Extract editable text from scans
1. Capture the image and enter gallery mode (Steps 1-6 above.)
2. Click on the “OCR” icon to activate optical character recognition.
3. Select the primary language of the target document. If the document has two languages, select both the primary and secondary languages.
4. Click “Run” to extract text. Extraction may take 2 to 3 minutes, depending on the amount of text.
5. Click “Save” to confirm and save the extracted text file or click on “Exit” to cancel extraction.
Method 2: Extract editable text from JPG or PNG
1. Go to gallery mode and click on “Import image file” to import a JPG or PNG file to the gallery.
2. Click on the “OCR” icon to activate optical character recognition.
3. Select the primary language of the target document. If the document has two languages, select both the primary and secondary languages.
4. Click “Run” to extract text. Extraction may take 2 to 3 minutes, depending on the amount of text.
5. Click “Save” to confirm and save the extracted text file or click on “Exit” to cancel extraction. Βασικές Πληροφορίες Επέκτασης
| Όνομα |  Documate OCR Documate OCR |
| ID | phiedbebmmcaeemplngfafginbilgikp |
| Επίσημο URL | https://chromewebstore.google.com/detail/documate-ocr/phiedbebmmcaeemplngfafginbilgikp |
| Περιγραφή | Documate OCR |
| Μέγεθος Αρχείου | 59.67 MB |
| Αριθμός Εγκαταστάσεων | 2,151 |
| Τρέχουσα Έκδοση | 1.1.0908 |
| Τελευταία Ενημέρωση | 2022-09-14 |
| Ημερομηνία Δημοσίευσης | 2021-02-28 |
| Αξιολόγηση | 2.50/5 Συνολικά 2 Αξιολογήσεις |
| Προγραμματιστής | inswanmarket |
| Ηλεκτρονικό ταχυδρομείο | [email protected] |
| Τύπος Πληρωμής | free |
| URL της Σελίδας Πολιτικής Απορρήτου | https://www.inswan.com/en/privacy |
| Υποστηριζόμενες Γλώσσες | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"name": "Documate OCR",
"version": "1.1.0908",
"description": "Documate OCR",
"manifest_version": 3,
"action": {
"default_popup": "index.html"
},
"background": {
"service_worker": "background.js"
},
"icons": {
"240": "icon.png"
},
"permissions": [
"storage",
"management"
],
"externally_connectable": {
"ids": [
"*"
]
},
"web_accessible_resources": [
{
"resources": [
"js\/worker.min.js",
"js\/tessearct.min.wasm.js",
"js\/tessearct-core.wasm.js",
"traineddata\/*.traineddata.gz"
],
"matches": []
}
],
"key": "MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAoJP6\/\/849CpsVHtS+NwCjf2GyVnc3oGk7cRgcLzMwddw\/VaZ7rGz5Dw1tXt9HvfPz4IQ98se4i6062JvV0DzpQSdKFbEhaczmp2uwhj5zbvNcjV96p+QwUL5MmnxEFNsRwuzXz5kEEHtJ52m5ducigrQFSa1e4qBbyQnjCq9Du5J+RhPrbvDxLYxTvlGeD\/KBv+dqGvimK+eJfjr1p\/87\/vtpQvOqV4V5d5LXFCj0kcE0rKqso7ckuPUvUnUAVXUbs7W+rV5VWSj5aRkWlXbvA3u6CQIa4uMLJfPCxkT051bwOYJdP37vsx0rCglr3soYBrEHrUIbZ9CtGmuILHnKwIDAQAB"
} | |











