ISBN Extractor
Automatically extract all ISBN from a webpage.
¿Qué es ISBN Extractor?
ISBN Extractor es una extensión de Chrome desarrollada por Ray, y su función principal es "Automatically extract all ISBN from a webpage.".
Capturas de Pantalla de la Extensión
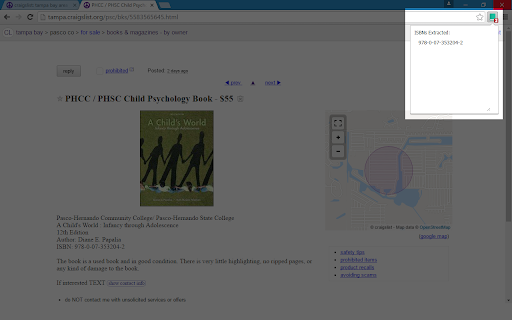
Descargar Archivo CRX de la Extensión ISBN Extractor
Descarga archivos de extensión ISBN Extractor en formato crx, instala manualmente las extensiones de Chrome en el navegador o comparte los archivos crx con amigos para instalar fácilmente las extensiones de Chrome.
Instrucciones de Uso de la Extensión
This is a simple extension that will extract all ISBN from any web page.
Extracts all 10 or 13 digit ISBNs (even if separated by spaces or -).
If you want to make the list comma separated or anything like that I recommend http://sortmylist.com/
**Update Version 1.1 **
Updated ISBN matching pattern.
ISBN scraping now is a bit cleaner
Updated to latest Google APIs
Fixed problem of not extracting after switching tabs Información Básica de la Extensión
| Nombre |  ISBN Extractor ISBN Extractor |
| ID | bjillcfelggegochlahahhlfcgfmddip |
| URL Oficial | https://chromewebstore.google.com/detail/isbn-extractor/bjillcfelggegochlahahhlfcgfmddip |
| Descripción | Automatically extract all ISBN from a webpage. |
| Tamaño del Archivo | 535 KB |
| Cantidad de Instalaciones | 479 |
| Versión Actual | 1.1.2 |
| Última Actualización | 2022-04-23 |
| Fecha de Publicación | 2016-06-21 |
| Calificación | 4.75/5 Total de 4 Calificaciones |
| Desarrollador | Ray |
| Correo electrónico | [email protected] |
| Tipo de Pago | free |
| Idiomas Soportados | en-US |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"manifest_version": 2,
"name": "ISBN Extractor",
"offline_enabled": true,
"permissions": [
"webNavigation",
"chrome:\/\/favicon\/",
"https:\/\/*\/*",
"http:\/\/*\/*",
"tabs",
"storage"
],
"version": "1.1.2",
"content_security_policy": "script-src 'self' https:\/\/ssl.google-analytics.com; object-src 'self'",
"background": {
"scripts": [
"js\/background.js"
],
"persistent": true
},
"browser_action": {
"default_icon": "icons\/icon512.png",
"default_title": "ISBN Extractor!",
"default_popup": "src\/page_action\/page_action.html"
},
"content_scripts": [
{
"js": [
"js\/content.js"
],
"matches": [
"http:\/\/*\/*",
"https:\/\/*\/*",
"file:\/\/*"
],
"run_at": "document_end"
}
],
"description": "Automatically extract all ISBN from a webpage.",
"icons": {
"512": "icons\/icon512.png"
}
} | |











