Image Reader (OCR)
Easily get words out of an image with OCR engine!
¿Qué es Image Reader (OCR)?
Image Reader (OCR) es una extensión de Chrome desarrollada por Sevina, y su función principal es "Easily get words out of an image with OCR engine!".
Capturas de Pantalla de la Extensión
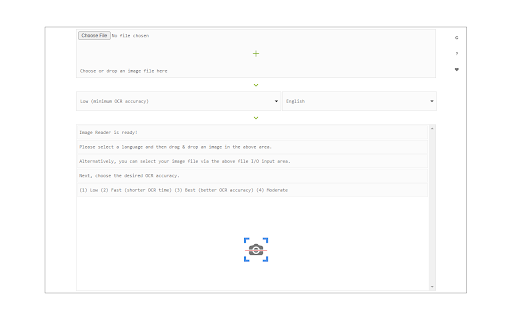

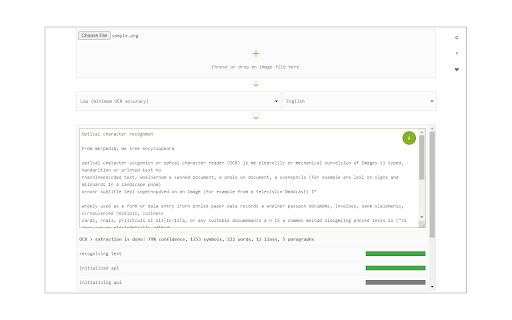
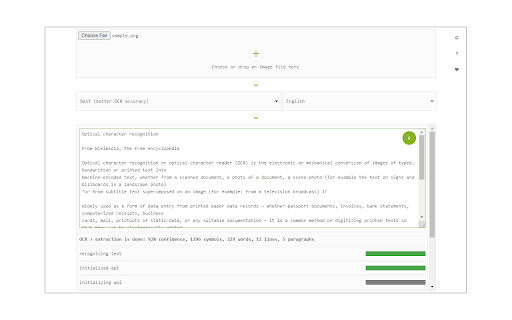
Descargar Archivo CRX de la Extensión Image Reader (OCR)
Descarga archivos de extensión Image Reader (OCR) en formato crx, instala manualmente las extensiones de Chrome en el navegador o comparte los archivos crx con amigos para instalar fácilmente las extensiones de Chrome.
Instrucciones de Uso de la Extensión
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info.
To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English.
Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package.
To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html). Información Básica de la Extensión
| Nombre |  Image Reader (OCR) Image Reader (OCR) |
| ID | cakcfocedphbadddjpalejbkhflfbhmf |
| URL Oficial | https://chromewebstore.google.com/detail/image-reader-ocr/cakcfocedphbadddjpalejbkhflfbhmf |
| Descripción | Easily get words out of an image with OCR engine! |
| Tamaño del Archivo | 7.51 MB |
| Cantidad de Instalaciones | 31,444 |
| Versión Actual | 0.1.7 |
| Última Actualización | 2023-12-07 |
| Fecha de Publicación | 2019-08-27 |
| Calificación | 3.85/5 Total de 20 Calificaciones |
| Desarrollador | Sevina |
| Correo electrónico | [email protected] |
| Tipo de Pago | free |
| Sitio Web de la Extensión | https://mybrowseraddon.com/image-reader.html |
| URL de la Página de Ayuda | https://mybrowseraddon.com/image-reader.html |
| URL de la Página de Política de Privacidad | https://mybrowseraddon.com/privacy-policy/developer/sevina.html |
| Idiomas Soportados | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"version": "0.1.7",
"manifest_version": 3,
"offline_enabled": true,
"name": "Image Reader (OCR)",
"permissions": [
"storage",
"contextMenus"
],
"homepage_url": "https:\/\/mybrowseraddon.com\/image-reader.html",
"description": "Easily get words out of an image with OCR engine!",
"commands": {
"_execute_action": []
},
"background": {
"service_worker": "background.js"
},
"content_security_policy": {
"extension_pages": "script-src 'self' 'wasm-unsafe-eval'; object-src 'self'"
},
"action": {
"default_title": "Image Reader (OCR)",
"default_icon": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png"
}
},
"icons": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png",
"128": "data\/icons\/128.png"
}
} | |











