ISBN Extractor
Automatically extract all ISBN from a webpage.
What is ISBN Extractor?
ISBN Extractor is a Chrome extension developed by Ray, and its main feature is "Automatically extract all ISBN from a webpage.".
Extension Screenshots
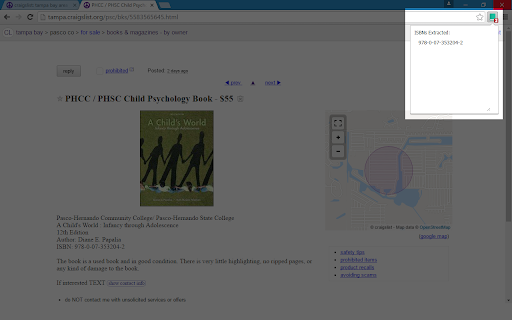
Download ISBN Extractor Extension CRX File
Download ISBN Extractor extension files in crx format, manually install Chrome extensions in the browser, or share the crx files with friends to easily install Chrome extensions.
Extension Usage Instructions
This is a simple extension that will extract all ISBN from any web page. Extracts all 10 or 13 digit ISBNs (even if separated by spaces or -). If you want to make the list comma separated or anything like that I recommend http://sortmylist.com/ **Update Version 1.1 ** Updated ISBN matching pattern. ISBN scraping now is a bit cleaner Updated to latest Google APIs Fixed problem of not extracting after switching tabs
Extension Basic Information
| Name |  ISBN Extractor ISBN Extractor |
| ID | bjillcfelggegochlahahhlfcgfmddip |
| Official URL | https://chromewebstore.google.com/detail/isbn-extractor/bjillcfelggegochlahahhlfcgfmddip |
| Description | Automatically extract all ISBN from a webpage. |
| File Size | 535 KB |
| Installation Count | 479 |
| Current Version | 1.1.2 |
| Last Updated | 2022-04-23 |
| Publish Date | 2016-06-21 |
| Rating | 4.75/5 Total 4 Ratings |
| Developer | Ray |
| 2c6az985r@mozmail.com | |
| Payment Type | free |
| Supported Languages | en-US |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"manifest_version": 2,
"name": "ISBN Extractor",
"offline_enabled": true,
"permissions": [
"webNavigation",
"chrome:\/\/favicon\/",
"https:\/\/*\/*",
"http:\/\/*\/*",
"tabs",
"storage"
],
"version": "1.1.2",
"content_security_policy": "script-src 'self' https:\/\/ssl.google-analytics.com; object-src 'self'",
"background": {
"scripts": [
"js\/background.js"
],
"persistent": true
},
"browser_action": {
"default_icon": "icons\/icon512.png",
"default_title": "ISBN Extractor!",
"default_popup": "src\/page_action\/page_action.html"
},
"content_scripts": [
{
"js": [
"js\/content.js"
],
"matches": [
"http:\/\/*\/*",
"https:\/\/*\/*",
"file:\/\/*"
],
"run_at": "document_end"
}
],
"description": "Automatically extract all ISBN from a webpage.",
"icons": {
"512": "icons\/icon512.png"
}
} | |











