PDF Extractor
This extension helps the user to extract PDF links and create a download page for all the PDF's on the tesseractonline.com website.
What is PDF Extractor?
PDF Extractor is a Chrome extension developed by Aditya, and its main feature is "This extension helps the user to extract PDF links and create a download page for all the PDF's on the tesseractonline.com website.".
Extension Screenshots
Download PDF Extractor Extension CRX File
Download PDF Extractor extension files in crx format, manually install Chrome extensions in the browser, or share the crx files with friends to easily install Chrome extensions.
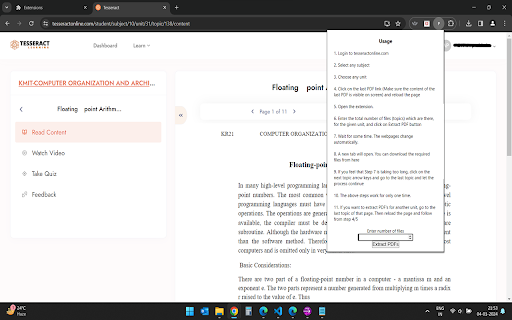
Extension Usage Instructions
Enhance your experience on tesseractonline.com with the PDF Extractor Chrome extension! This powerful tool simplifies the process of extracting PDF links, allowing you to effortlessly create a convenient download page for all the PDF files available on the website.
Extension Basic Information
| Name |  PDF Extractor PDF Extractor |
| ID | mpijfmkbemcfeopdjmffocfbidnokdki |
| Official URL | https://chromewebstore.google.com/detail/pdf-extractor/mpijfmkbemcfeopdjmffocfbidnokdki |
| Description | This extension helps the user to extract PDF links and create a download page for all the PDF's on the tesseractonline.com website. |
| File Size | 14.11 KB |
| Installation Count | 28 |
| Current Version | 0.0.0.1 |
| Last Updated | 2024-01-06 |
| Publish Date | 2024-01-06 |
| Rating | 5.00/5 Total 1 Ratings |
| Developer | Aditya |
| adityaprabhala03@gmail.com | |
| Payment Type | free |
| Supported Languages | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"manifest_version": 3,
"name": "PDF Extractor",
"version": "0.0.0.1",
"icons": {
"16": "icon16.png",
"48": "icon48.png",
"128": "icon128.png"
},
"description": "This extension helps the user to extract PDF links and create a download page for all the PDF's on the tesseractonline.com website.",
"action": {
"default_popup": "popup.html"
},
"content_scripts": [
{
"matches": [
"https:\/\/tesseractonline.com\/*"
],
"js": [
"content.js"
]
}
]
} | |











