ISBN Extractor
Automatically extract all ISBN from a webpage.
Qu'est-ce que ISBN Extractor ?
ISBN Extractor est une extension Chrome développée par Ray, et sa fonction principale est "Automatically extract all ISBN from a webpage.".
Captures d'Écran de l'Extension
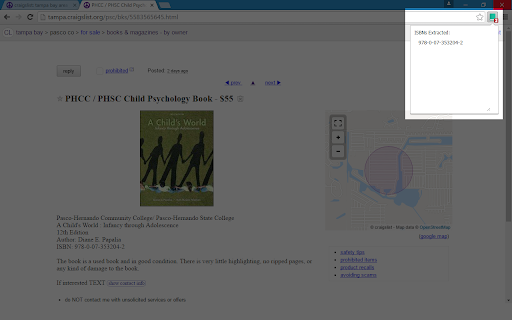
Télécharger le fichier CRX de l'extension ISBN Extractor
Téléchargez les fichiers d'extension ISBN Extractor au format crx, installez manuellement les extensions Chrome dans le navigateur ou partagez les fichiers crx avec des amis pour installer facilement les extensions Chrome.
Instructions d'Utilisation de l'Extension
This is a simple extension that will extract all ISBN from any web page. Extracts all 10 or 13 digit ISBNs (even if separated by spaces or -). If you want to make the list comma separated or anything like that I recommend http://sortmylist.com/ **Update Version 1.1 ** Updated ISBN matching pattern. ISBN scraping now is a bit cleaner Updated to latest Google APIs Fixed problem of not extracting after switching tabs
Informations de Base sur l'Extension
| Nom |  ISBN Extractor ISBN Extractor |
| ID | bjillcfelggegochlahahhlfcgfmddip |
| URL Officiel | https://chromewebstore.google.com/detail/isbn-extractor/bjillcfelggegochlahahhlfcgfmddip |
| Description | Automatically extract all ISBN from a webpage. |
| Taille du Fichier | 535 KB |
| Nombre d'Installations | 479 |
| Version Actuelle | 1.1.2 |
| Dernière Mise à Jour | 2022-04-23 |
| Date de Publication | 2016-06-21 |
| Évaluation | 4.75/5 Total 4 Évaluations |
| Développeur | Ray |
| 2c6az985r@mozmail.com | |
| Type de Paiement | free |
| Langues Prises en Charge | en-US |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"manifest_version": 2,
"name": "ISBN Extractor",
"offline_enabled": true,
"permissions": [
"webNavigation",
"chrome:\/\/favicon\/",
"https:\/\/*\/*",
"http:\/\/*\/*",
"tabs",
"storage"
],
"version": "1.1.2",
"content_security_policy": "script-src 'self' https:\/\/ssl.google-analytics.com; object-src 'self'",
"background": {
"scripts": [
"js\/background.js"
],
"persistent": true
},
"browser_action": {
"default_icon": "icons\/icon512.png",
"default_title": "ISBN Extractor!",
"default_popup": "src\/page_action\/page_action.html"
},
"content_scripts": [
{
"js": [
"js\/content.js"
],
"matches": [
"http:\/\/*\/*",
"https:\/\/*\/*",
"file:\/\/*"
],
"run_at": "document_end"
}
],
"description": "Automatically extract all ISBN from a webpage.",
"icons": {
"512": "icons\/icon512.png"
}
} | |











