Image Reader (OCR)
Easily get words out of an image with OCR engine!
Qu'est-ce que Image Reader (OCR) ?
Image Reader (OCR) est une extension Chrome développée par Sevina, et sa fonction principale est "Easily get words out of an image with OCR engine!".
Captures d'Écran de l'Extension
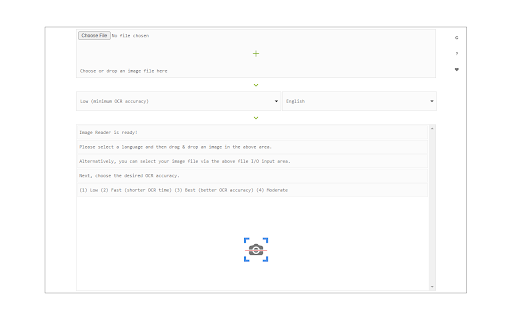

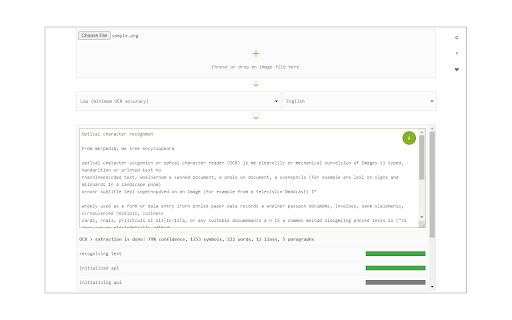
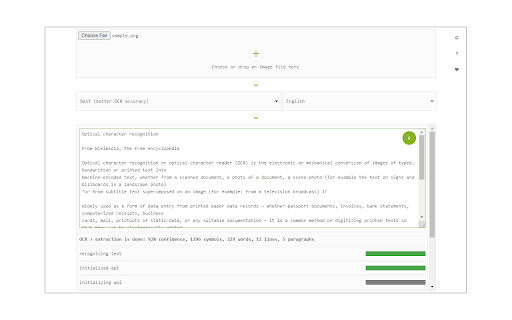
Télécharger le fichier CRX de l'extension Image Reader (OCR)
Téléchargez les fichiers d'extension Image Reader (OCR) au format crx, installez manuellement les extensions Chrome dans le navigateur ou partagez les fichiers crx avec des amis pour installer facilement les extensions Chrome.
Instructions d'Utilisation de l'Extension
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info.
To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English.
Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package.
To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html). Informations de Base sur l'Extension
| Nom |  Image Reader (OCR) Image Reader (OCR) |
| ID | cakcfocedphbadddjpalejbkhflfbhmf |
| URL Officiel | https://chromewebstore.google.com/detail/image-reader-ocr/cakcfocedphbadddjpalejbkhflfbhmf |
| Description | Easily get words out of an image with OCR engine! |
| Taille du Fichier | 7.51 MB |
| Nombre d'Installations | 31,444 |
| Version Actuelle | 0.1.7 |
| Dernière Mise à Jour | 2023-12-07 |
| Date de Publication | 2019-08-27 |
| Évaluation | 3.85/5 Total 20 Évaluations |
| Développeur | Sevina |
| [email protected] | |
| Type de Paiement | free |
| Site Web de l'Extension | https://mybrowseraddon.com/image-reader.html |
| URL de la Page d'Aide | https://mybrowseraddon.com/image-reader.html |
| URL de la Page de Politique de Confidentialité | https://mybrowseraddon.com/privacy-policy/developer/sevina.html |
| Langues Prises en Charge | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"version": "0.1.7",
"manifest_version": 3,
"offline_enabled": true,
"name": "Image Reader (OCR)",
"permissions": [
"storage",
"contextMenus"
],
"homepage_url": "https:\/\/mybrowseraddon.com\/image-reader.html",
"description": "Easily get words out of an image with OCR engine!",
"commands": {
"_execute_action": []
},
"background": {
"service_worker": "background.js"
},
"content_security_policy": {
"extension_pages": "script-src 'self' 'wasm-unsafe-eval'; object-src 'self'"
},
"action": {
"default_title": "Image Reader (OCR)",
"default_icon": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png"
}
},
"icons": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png",
"128": "data\/icons\/128.png"
}
} | |











