ISBN Extractor
Automatically extract all ISBN from a webpage.
ISBN Extractor क्या है?
ISBN Extractor Ray द्वारा विकसित एक क्रोम एक्सटेंशन है, और इसकी मुख्य विशेषता है "Automatically extract all ISBN from a webpage."।
एक्सटेंशन स्क्रीनशॉट्स
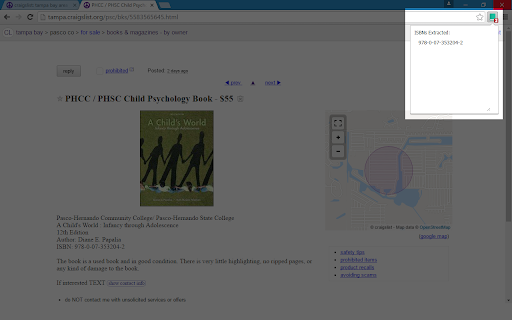
एक्सएक्स एक्सटेंशन CRX फ़ाइल डाउनलोड करें
crx प्रारूप में ISBN Extractor एक्सटेंशन फ़ाइलें डाउनलोड करें, ब्राउज़र में क्रोम एक्सटेंशन को मैन्युअल रूप से स्थापित करें या दोस्तों के साथ crx फ़ाइलों को साझा करें ताकि क्रोम एक्सटेंशन को आसानी से स्थापित किया जा सके।
एक्सटेंशन उपयोग निर्देश
This is a simple extension that will extract all ISBN from any web page.
Extracts all 10 or 13 digit ISBNs (even if separated by spaces or -).
If you want to make the list comma separated or anything like that I recommend http://sortmylist.com/
**Update Version 1.1 **
Updated ISBN matching pattern.
ISBN scraping now is a bit cleaner
Updated to latest Google APIs
Fixed problem of not extracting after switching tabs एक्सटेंशन की मूल जानकारी
| नाम |  ISBN Extractor ISBN Extractor |
| ID | bjillcfelggegochlahahhlfcgfmddip |
| आधिकारिक URL | https://chromewebstore.google.com/detail/isbn-extractor/bjillcfelggegochlahahhlfcgfmddip |
| विवरण | Automatically extract all ISBN from a webpage. |
| फ़ाइल का आकार | 535 KB |
| स्थापना संख्या | 479 |
| वर्तमान संस्करण | 1.1.2 |
| अंतिम अपडेट | 2022-04-23 |
| प्रकाशन तिथि | 2016-06-21 |
| रेटिंग | 4.75/5 कुल 4 रेटिंग्स |
| डेवलपर | Ray |
| ईमेल | [email protected] |
| भुगतान के प्रकार | free |
| समर्थित भाषाएँ | en-US |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"manifest_version": 2,
"name": "ISBN Extractor",
"offline_enabled": true,
"permissions": [
"webNavigation",
"chrome:\/\/favicon\/",
"https:\/\/*\/*",
"http:\/\/*\/*",
"tabs",
"storage"
],
"version": "1.1.2",
"content_security_policy": "script-src 'self' https:\/\/ssl.google-analytics.com; object-src 'self'",
"background": {
"scripts": [
"js\/background.js"
],
"persistent": true
},
"browser_action": {
"default_icon": "icons\/icon512.png",
"default_title": "ISBN Extractor!",
"default_popup": "src\/page_action\/page_action.html"
},
"content_scripts": [
{
"js": [
"js\/content.js"
],
"matches": [
"http:\/\/*\/*",
"https:\/\/*\/*",
"file:\/\/*"
],
"run_at": "document_end"
}
],
"description": "Automatically extract all ISBN from a webpage.",
"icons": {
"512": "icons\/icon512.png"
}
} | |











