Tapicker - Powerful Web Data Scraper
A powerful web data scraper that supports extracting data from any website into Excel, CSV or JSON files without writing any code.
Apa itu Tapicker - Powerful Web Data Scraper?
Tapicker - Powerful Web Data Scraper adalah ekstensi Chrome yang dikembangkan oleh https://tapicker.com, dan fitur utamanya adalah "A powerful web data scraper that supports extracting data from any website into Excel, CSV or JSON files without writing any code.".
Screenshot Ekstensi




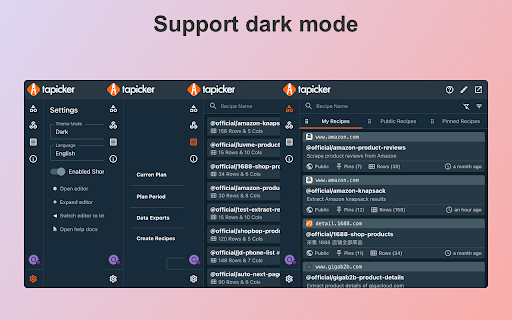




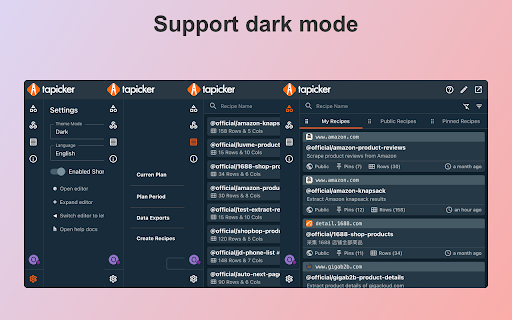
Unduh Berkas CRX Ekstensi Tapicker - Powerful Web Data Scraper
Unduh file ekstensi Tapicker - Powerful Web Data Scraper dalam format crx, pasang ekstensi Chrome secara manual di peramban, atau bagikan file crx dengan teman untuk menginstal ekstensi Chrome dengan mudah.
Petunjuk Penggunaan Ekstensi
Tapicker is a powerful web data scraper that supports extracting data from any website into Excel, CSV or JSON files without writing any code.
Tapicker is also a web RPA that allows you to run some automated tasks in the browser.
🎉 New upgrade v3.0 🎉
Tapicker is very easy to use and does not require computer skills, just a few clicks to collect data.
Tapicker can even simulate human behavior to visit the target website.
💡 Key Feature Highlights:
★ Free Public Recipes (the number is constantly increasing++)
★ Deep Web Scraping (e.g. crawling Google search results, e-commerce website products, etc.)
★ Multi-block Data Scraping (multiple blocks of data can be scraped at once on the same page)
★ Batch Web Scraping (support to scrape multiple detail pages and search multiple keywords at the same time)
★ Auto-fill Form (e.g. enter text, click button, check options, etc.)
★ Submit Form (e.g. keyword search, login, register, etc.)
★ Automatic Next Page ( e.g. click next page button, infinite scroll loading, etc.)
★ Data Transformation (support for setting up a series of transformers for each column to trim the data)
★ Prevent Data Duplication (support custom unique keys to avoid duplicate rows)
★ Visual Recipe Editor (easily create recipes with no need for coding)
★ Private Page Support (some pages that require login to access)
★ Single Page Application Support (pages developed by React, Vue, Angular, etc.)
★ Map Data Extraction (e.g. Zillow, Redfin, Google Map data scraping)
★ Webhooks Support (automatically push to you after scraping data)
★ Export Data Support (export as .xls, .xlsx, .csv, .json, .xml, .txt files)
What is Tapicker?
A visual no-code web scraper. A web data collector/extractor, A web RPA, A web crawler, A email finder.
Can I use Tapicker for free?
Absolutely! Tapicker's free plan is very user-friendly. When you need a higher program limit, you can always upgrade to the Plus or Pro plans.
Is my data secure?
The data you scraped is stored in your browser and we do not access and upload it, much less sell it.
What websites can I scrape using Tapicker?
Any website as long as you can access it.
Here are some use cases for Tapicker:
☞ Scraping search results from Google, Bing and other search engines.
☞ Extract product information from e-commerce sites such as Amazon, Etsy, Shopee, etc.
☞ Find and extract hidden email addresses from websites to complete sales lead collection.
☞ Scraping data from relevant industry websites to train machine learning, just like ChatGPT.
☞ Scrape data from social media sites like Twitter and Facebook for potential business opportunities.
☞ Scraping Reddit posts to discover people's topic preferences, product needs, and product reviews.
☞ Collect contact information from LinkedIn to expand your network.
What can Tapicker be used for?
☞ Customer Development - Mining & collecting potential customers' emails, phone numbers, social accounts and other contact information
☞ E-commerce - product data extraction, product price capture, description, URL extraction, image capture, etc.
☞ Retail Analysis - Analyze competitor or supplier pricing, inventory, sales, etc.
☞ Brand word of mouth - crawl product reviews, social content, etc. for sentiment analysis
☞ Business Intelligence - Collect key business intelligence, know yourself and the enemy, and be safe in a hundred battles
☞ Talent Think Tank - Quickly collect candidate resumes for HR or headhunters
☞ News Extraction - Extract information from news portals, blogs, forums, etc.
☞ Academic research - extract data for machine learning, business strategy research
☞ More interesting...
If you encounter any problems during use, please let me know ~
[email protected] Informasi Dasar Ekstensi
| Nama |  Tapicker - Powerful Web Data Scraper Tapicker - Powerful Web Data Scraper |
| ID | baglkjackdnhdpjjcjpkhmemggiklhid |
| URL Resmi | https://chromewebstore.google.com/detail/tapicker-powerful-web-dat/baglkjackdnhdpjjcjpkhmemggiklhid |
| Deskripsi | A powerful web data scraper that supports extracting data from any website into Excel, CSV or JSON files without writing any code. |
| Ukuran File | 589 KB |
| Jumlah Instalasi | 4,000 |
| Versi Saat Ini | 3.13.6 |
| Terakhir Diperbarui | 2023-08-20 |
| Tanggal Publikasi | 2022-02-28 |
| Penilaian | 4.30/5 Total 10 Penilaian |
| Pengembang | https://tapicker.com |
| [email protected] | |
| Tipe Pembayaran | free |
| Situs Ekstensi | https://www.tapicker.com |
| URL Halaman Bantuan | https://www.tapicker.com |
| URL Halaman Kebijakan Privasi | https://www.tapicker.com/privacy |
| Bahasa yang Didukung | en,zh-CN |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"version": "3.13.6",
"name": "__MSG_ext_name__",
"description": "__MSG_ext_intro__",
"default_locale": "en",
"manifest_version": 3,
"icons": {
"16": "images\/icon16.png",
"32": "images\/icon32.png",
"48": "images\/icon48.png",
"128": "images\/icon128.png"
},
"commands": {
"_execute_action": {
"suggested_key": {
"windows": "Alt+P",
"mac": "Alt+P",
"chromeos": "Alt+P",
"linux": "Alt+P"
}
}
},
"action": {
"default_popup": "app.html#\/popup\/recipes"
},
"content_scripts": [
{
"matches": [
"http:\/\/*\/*",
"https:\/\/*\/*"
],
"run_at": "document_end",
"js": [
"content.js"
]
}
],
"background": {
"service_worker": "background.js"
},
"web_accessible_resources": [
{
"resources": [
"app.html",
"content.css",
"bridge.js",
"images\/icon48.png"
],
"matches": [
"http:\/\/*\/*",
"https:\/\/*\/*"
]
}
],
"permissions": [
"activeTab",
"scripting",
"storage",
"unlimitedStorage",
"webNavigation",
"notifications"
],
"host_permissions": [
"http:\/\/*\/*",
"https:\/\/*\/*"
]
} | |











