Image Reader (OCR)
Easily get words out of an image with OCR engine!
Image Reader (OCR)とは何ですか?
Image Reader (OCR)はSevinaによって開発されたChromeの拡張機能で、その主な機能は「Easily get words out of an image with OCR engine!」です。
拡張機能のスクリーンショット
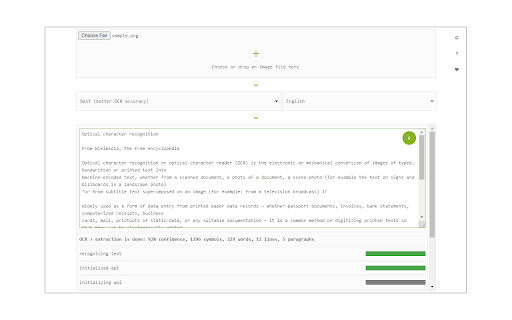
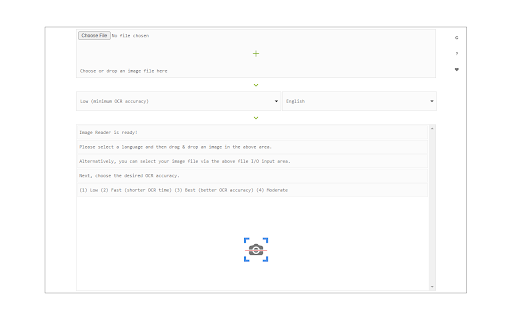

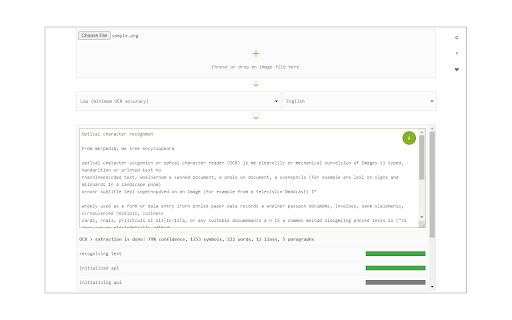
Image Reader (OCR)拡張機能のCRXファイルをダウンロード
Image Reader (OCR)拡張子のファイルをcrx形式でダウンロードし、ブラウザにChrome拡張機能を手動でインストールするか、crxファイルを友達と共有して簡単にChrome拡張機能をインストールします。
拡張機能の使用方法
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info. To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English. Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package. To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html).
拡張機能の基本情報
| 名前 |  Image Reader (OCR) Image Reader (OCR) |
| ID | cakcfocedphbadddjpalejbkhflfbhmf |
| 公式URL | https://chromewebstore.google.com/detail/image-reader-ocr/cakcfocedphbadddjpalejbkhflfbhmf |
| 説明 | Easily get words out of an image with OCR engine! |
| ファイルサイズ | 7.51 MB |
| インストール数 | 31,444 |
| 現在のバージョン | 0.1.7 |
| 最終更新日 | 2023-12-07 |
| 公開日 | 2019-08-27 |
| 評価 | 3.85/5 合計 20 レビュー |
| 開発者 | Sevina |
| Eメール | sevina.lucia@gmail.com |
| 支払い方法 | free |
| 拡張機能のウェブサイト | https://mybrowseraddon.com/image-reader.html |
| ヘルプページのURL | https://mybrowseraddon.com/image-reader.html |
| プライバシーポリシーページのURL | https://mybrowseraddon.com/privacy-policy/developer/sevina.html |
| 対応言語 | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"version": "0.1.7",
"manifest_version": 3,
"offline_enabled": true,
"name": "Image Reader (OCR)",
"permissions": [
"storage",
"contextMenus"
],
"homepage_url": "https:\/\/mybrowseraddon.com\/image-reader.html",
"description": "Easily get words out of an image with OCR engine!",
"commands": {
"_execute_action": []
},
"background": {
"service_worker": "background.js"
},
"content_security_policy": {
"extension_pages": "script-src 'self' 'wasm-unsafe-eval'; object-src 'self'"
},
"action": {
"default_title": "Image Reader (OCR)",
"default_icon": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png"
}
},
"icons": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png",
"128": "data\/icons\/128.png"
}
} | |











