ISBN Extractor
Automatically extract all ISBN from a webpage.
ISBN Extractor란 무엇입니까?
ISBN Extractor은(는) Ray에 의해 개발된 Chrome 확장 프로그램으로, 주요 기능은 "Automatically extract all ISBN from a webpage."입니다.
확장 프로그램 스크린샷
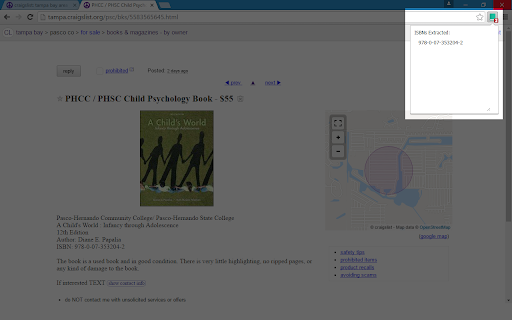
ISBN Extractor 확장 프로그램 CRX 파일 다운로드
크롬 확장 프로그램을 crx 형식으로 다운로드하여 브라우저에 수동으로 설치하거나 crx 파일을 친구들과 공유하여 쉽게 크롬 확장 프로그램을 설치하세요.
확장 프로그램 사용 설명서
This is a simple extension that will extract all ISBN from any web page.
Extracts all 10 or 13 digit ISBNs (even if separated by spaces or -).
If you want to make the list comma separated or anything like that I recommend http://sortmylist.com/
**Update Version 1.1 **
Updated ISBN matching pattern.
ISBN scraping now is a bit cleaner
Updated to latest Google APIs
Fixed problem of not extracting after switching tabs 확장 프로그램 기본 정보
| 이름 |  ISBN Extractor ISBN Extractor |
| ID | bjillcfelggegochlahahhlfcgfmddip |
| 공식 URL | https://chromewebstore.google.com/detail/isbn-extractor/bjillcfelggegochlahahhlfcgfmddip |
| 설명 | Automatically extract all ISBN from a webpage. |
| 파일 크기 | 535 KB |
| 설치 횟수 | 479 |
| 현재 버전 | 1.1.2 |
| 최근 업데이트 | 2022-04-23 |
| 출시 날짜 | 2016-06-21 |
| 평점 | 4.75/5 총 4 개의 평점 |
| 개발자 | Ray |
| 이메일 | [email protected] |
| 결제 유형 | free |
| 지원되는 언어 | en-US |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"manifest_version": 2,
"name": "ISBN Extractor",
"offline_enabled": true,
"permissions": [
"webNavigation",
"chrome:\/\/favicon\/",
"https:\/\/*\/*",
"http:\/\/*\/*",
"tabs",
"storage"
],
"version": "1.1.2",
"content_security_policy": "script-src 'self' https:\/\/ssl.google-analytics.com; object-src 'self'",
"background": {
"scripts": [
"js\/background.js"
],
"persistent": true
},
"browser_action": {
"default_icon": "icons\/icon512.png",
"default_title": "ISBN Extractor!",
"default_popup": "src\/page_action\/page_action.html"
},
"content_scripts": [
{
"js": [
"js\/content.js"
],
"matches": [
"http:\/\/*\/*",
"https:\/\/*\/*",
"file:\/\/*"
],
"run_at": "document_end"
}
],
"description": "Automatically extract all ISBN from a webpage.",
"icons": {
"512": "icons\/icon512.png"
}
} | |











