Image Reader (OCR)
Easily get words out of an image with OCR engine!
Image Reader (OCR)란 무엇입니까?
Image Reader (OCR)은(는) Sevina에 의해 개발된 Chrome 확장 프로그램으로, 주요 기능은 "Easily get words out of an image with OCR engine!"입니다.
확장 프로그램 스크린샷
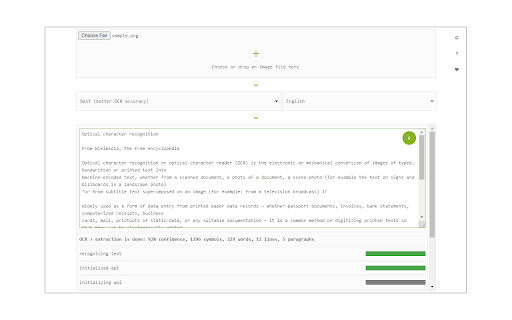
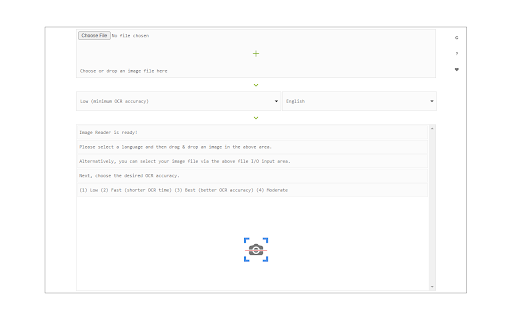

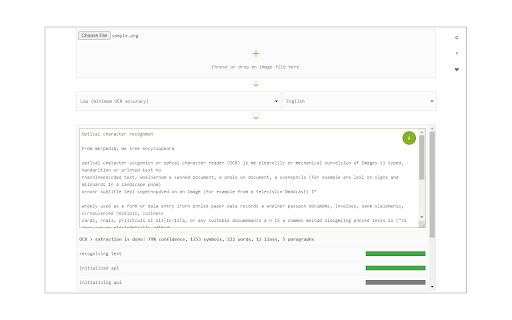
Image Reader (OCR) 확장 프로그램 CRX 파일 다운로드
크롬 확장 프로그램을 crx 형식으로 다운로드하여 브라우저에 수동으로 설치하거나 crx 파일을 친구들과 공유하여 쉽게 크롬 확장 프로그램을 설치하세요.
확장 프로그램 사용 설명서
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info. To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English. Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package. To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html).
확장 프로그램 기본 정보
| 이름 |  Image Reader (OCR) Image Reader (OCR) |
| ID | cakcfocedphbadddjpalejbkhflfbhmf |
| 공식 URL | https://chromewebstore.google.com/detail/image-reader-ocr/cakcfocedphbadddjpalejbkhflfbhmf |
| 설명 | Easily get words out of an image with OCR engine! |
| 파일 크기 | 7.51 MB |
| 설치 횟수 | 31,444 |
| 현재 버전 | 0.1.7 |
| 최근 업데이트 | 2023-12-07 |
| 출시 날짜 | 2019-08-27 |
| 평점 | 3.85/5 총 20 개의 평점 |
| 개발자 | Sevina |
| 이메일 | sevina.lucia@gmail.com |
| 결제 유형 | free |
| 확장 프로그램 웹 사이트 | https://mybrowseraddon.com/image-reader.html |
| 도움말 페이지 URL | https://mybrowseraddon.com/image-reader.html |
| 개인정보 보호 정책 페이지 URL | https://mybrowseraddon.com/privacy-policy/developer/sevina.html |
| 지원되는 언어 | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"version": "0.1.7",
"manifest_version": 3,
"offline_enabled": true,
"name": "Image Reader (OCR)",
"permissions": [
"storage",
"contextMenus"
],
"homepage_url": "https:\/\/mybrowseraddon.com\/image-reader.html",
"description": "Easily get words out of an image with OCR engine!",
"commands": {
"_execute_action": []
},
"background": {
"service_worker": "background.js"
},
"content_security_policy": {
"extension_pages": "script-src 'self' 'wasm-unsafe-eval'; object-src 'self'"
},
"action": {
"default_title": "Image Reader (OCR)",
"default_icon": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png"
}
},
"icons": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png",
"128": "data\/icons\/128.png"
}
} | |











