ORC Text Snap
Extract text from images with Optical Character Recognition
ORC Text Snap란 무엇입니까?
ORC Text Snap은(는) Jofen에 의해 개발된 Chrome 확장 프로그램으로, 주요 기능은 "Extract text from images with Optical Character Recognition"입니다.
확장 프로그램 스크린샷



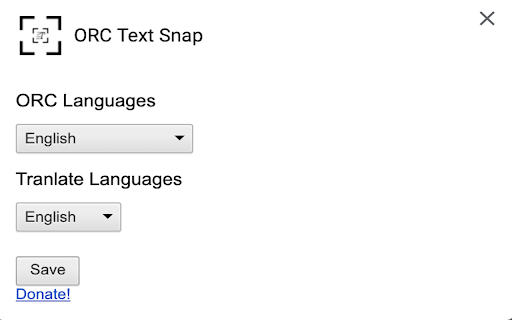
ORC Text Snap 확장 프로그램 CRX 파일 다운로드
크롬 확장 프로그램을 crx 형식으로 다운로드하여 브라우저에 수동으로 설치하거나 crx 파일을 친구들과 공유하여 쉽게 크롬 확장 프로그램을 설치하세요.
확장 프로그램 사용 설명서
Optical Character Recognition - Copy text from any image, video or PDF
===========
A handy tool to extract text from images, videos or PDF with just one click and crop instead of retyping the text character by character. A tipical use case is to copy any text from youtube videos, image formatted tutorials.
This tool copies text from images using the lightweight OCR engine [Tesseract.js](https://github.com/naptha/tesseract.js).
How to use it:
1. Click the icon, then select the area/image containing the text.
2. Wait until the tool to extract the text for you.
3. Extracted result will show in a text box. You can then click the copy button to load it into your Clipboard and Ctrl + V to paste it anywhere.
4. There is an option to translate the extracted text into your selected language.
5. You can define the ORC language and targeted translation languages on the options page. 확장 프로그램 기본 정보
| 이름 |  ORC Text Snap ORC Text Snap |
| ID | cjcbfnbbhjipgbbncobdgdpphnlalife |
| 공식 URL | https://chromewebstore.google.com/detail/orc-text-snap/cjcbfnbbhjipgbbncobdgdpphnlalife |
| 설명 | Extract text from images with Optical Character Recognition |
| 파일 크기 | 236 KB |
| 설치 횟수 | 1,886 |
| 현재 버전 | 1.1 |
| 최근 업데이트 | 2022-09-17 |
| 출시 날짜 | 2019-08-27 |
| 평점 | 2.00/5 총 5 개의 평점 |
| 개발자 | Jofen |
| 이메일 | [email protected] |
| 결제 유형 | free |
| 지원되는 언어 | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"name": "ORC Text Snap",
"description": "Extract text from images with Optical Character Recognition",
"version": "1.1",
"manifest_version": 2,
"background": {
"scripts": [
"dist\/main.js",
"js\/background.js"
],
"persistent": false
},
"browser_action": {
"default_icon": {
"19": "images\/icon19.png",
"38": "images\/icon38.png"
},
"default_title": "Extract text from images"
},
"options_ui": {
"page": "html\/options.html",
"open_in_tab": false,
"chrome_style": true
},
"icons": {
"16": "images\/icon16.png",
"48": "images\/icon48.png",
"128": "images\/icon128.png"
},
"homepage_url": "https:\/\/github.com\/jofen-chrome-extensions\/orc-text-snap",
"web_accessible_resources": [
"html\/iframe\/*",
"images\/Jcrop.gif",
"images\/pixel.png",
"images\/close.png"
],
"commands": {
"take-screenshot": {
"suggested_key": {
"default": "Alt+S"
},
"description": "Take Screenshot"
}
},
"permissions": [
"storage",
"tabs",
"activeTab",
"clipboardWrite"
],
"content_scripts": [
{
"matches": [
"*:\/\/*\/*"
],
"js": [
"vendor\/jquery.js",
"js\/inject.js"
],
"css": [
"css\/inject.css"
],
"run_at": "document_start"
}
],
"content_security_policy": "script-src 'self' 'unsafe-eval' https:\/\/cdn.jsdelivr.net; object-src 'self'"
} | |











