Image Reader (OCR)
Easily get words out of an image with OCR engine!
Wat is Image Reader (OCR)?
Image Reader (OCR) is een Chrome-extensie ontwikkeld door Sevina, en de belangrijkste functie is "Easily get words out of an image with OCR engine!".
Extensie Screenshots
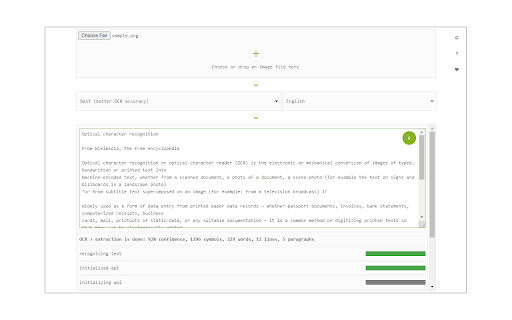
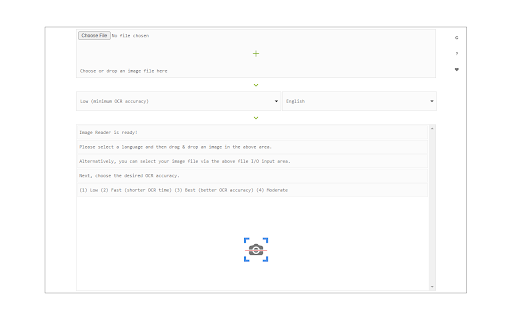

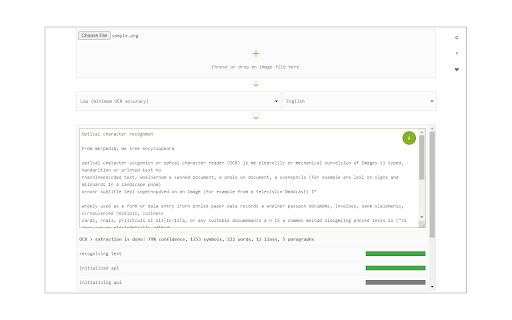
Download het CRX-bestand van de extensie Image Reader (OCR)
Download Image Reader (OCR)-extensiebestanden in crx-indeling, installeer Chrome-extensies handmatig in de browser of deel de crx-bestanden met vrienden om Chrome-extensies eenvoudig te installeren.
Instructies voor het Gebruik van de Extensie
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info. To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English. Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package. To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html).
Basisinformatie over de Extensie
| Naam |  Image Reader (OCR) Image Reader (OCR) |
| ID | cakcfocedphbadddjpalejbkhflfbhmf |
| Officiële URL | https://chromewebstore.google.com/detail/image-reader-ocr/cakcfocedphbadddjpalejbkhflfbhmf |
| Beschrijving | Easily get words out of an image with OCR engine! |
| Bestandsgrootte | 7.51 MB |
| Aantal Installaties | 31,444 |
| Huidige Versie | 0.1.7 |
| Laatst Bijgewerkt | 2023-12-07 |
| Publicatiedatum | 2019-08-27 |
| Beoordeling | 3.85/5 Totaal 20 Beoordelingen |
| Ontwikkelaar | Sevina |
| sevina.lucia@gmail.com | |
| Betalingswijze | free |
| Extensiewebsite | https://mybrowseraddon.com/image-reader.html |
| Help Pagina-URL | https://mybrowseraddon.com/image-reader.html |
| URL van de Privacybeleid Pagina | https://mybrowseraddon.com/privacy-policy/developer/sevina.html |
| Ondersteunde Talen | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"version": "0.1.7",
"manifest_version": 3,
"offline_enabled": true,
"name": "Image Reader (OCR)",
"permissions": [
"storage",
"contextMenus"
],
"homepage_url": "https:\/\/mybrowseraddon.com\/image-reader.html",
"description": "Easily get words out of an image with OCR engine!",
"commands": {
"_execute_action": []
},
"background": {
"service_worker": "background.js"
},
"content_security_policy": {
"extension_pages": "script-src 'self' 'wasm-unsafe-eval'; object-src 'self'"
},
"action": {
"default_title": "Image Reader (OCR)",
"default_icon": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png"
}
},
"icons": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png",
"128": "data\/icons\/128.png"
}
} | |











