Image Reader (OCR)
Easily get words out of an image with OCR engine!
Что такое Image Reader (OCR)?
Image Reader (OCR) - это расширение Chrome, разработанное Sevina, и его основная функция - "Easily get words out of an image with OCR engine!".
Снимки экрана расширения

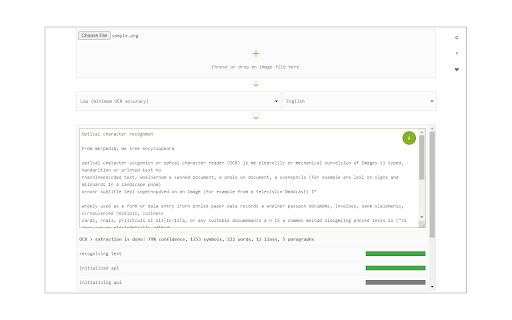
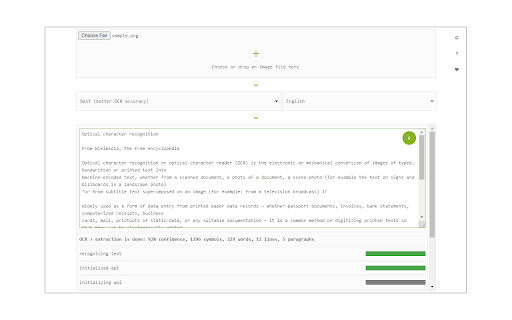
Скачать файл CRX расширения Image Reader (OCR)
Скачайте файлы расширений Image Reader (OCR) в формате crx, установите расширения Chrome вручную в браузере или поделитесь файлами crx с друзьями, чтобы легко установить расширения Chrome.
Инструкции по использованию расширения
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info.
To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English.
Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package.
To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html). Основная информация о расширении
| Название |  Image Reader (OCR) Image Reader (OCR) |
| ID | cakcfocedphbadddjpalejbkhflfbhmf |
| Официальный URL | https://chromewebstore.google.com/detail/image-reader-ocr/cakcfocedphbadddjpalejbkhflfbhmf |
| Описание | Easily get words out of an image with OCR engine! |
| Размер файла | 7.51 MB |
| Количество установок | 31,444 |
| Текущая Версия | 0.1.7 |
| Последнее Обновление | 2023-12-07 |
| Дата публикации | 2019-08-27 |
| Рейтинг | 3.85/5 Всего 20 оценок |
| Разработчик | Sevina |
| Электронная почта | [email protected] |
| Тип оплаты | free |
| Официальный сайт расширения | https://mybrowseraddon.com/image-reader.html |
| URL страницы помощи | https://mybrowseraddon.com/image-reader.html |
| URL страницы политики конфиденциальности | https://mybrowseraddon.com/privacy-policy/developer/sevina.html |
| Поддерживаемые языки | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"version": "0.1.7",
"manifest_version": 3,
"offline_enabled": true,
"name": "Image Reader (OCR)",
"permissions": [
"storage",
"contextMenus"
],
"homepage_url": "https:\/\/mybrowseraddon.com\/image-reader.html",
"description": "Easily get words out of an image with OCR engine!",
"commands": {
"_execute_action": []
},
"background": {
"service_worker": "background.js"
},
"content_security_policy": {
"extension_pages": "script-src 'self' 'wasm-unsafe-eval'; object-src 'self'"
},
"action": {
"default_title": "Image Reader (OCR)",
"default_icon": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png"
}
},
"icons": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png",
"128": "data\/icons\/128.png"
}
} | |











