ORC Text Snap
Extract text from images with Optical Character Recognition
Что такое ORC Text Snap?
ORC Text Snap - это расширение Chrome, разработанное Jofen, и его основная функция - "Extract text from images with Optical Character Recognition".
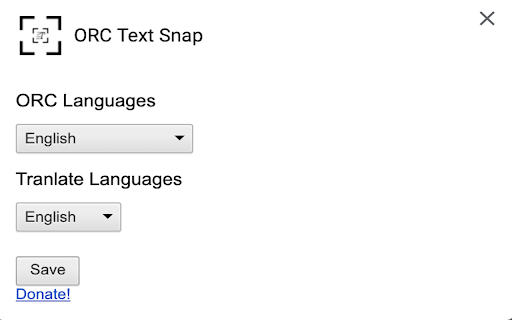
Снимки экрана расширения



Скачать файл CRX расширения ORC Text Snap
Скачайте файлы расширений ORC Text Snap в формате crx, установите расширения Chrome вручную в браузере или поделитесь файлами crx с друзьями, чтобы легко установить расширения Chrome.
Инструкции по использованию расширения
Optical Character Recognition - Copy text from any image, video or PDF
===========
A handy tool to extract text from images, videos or PDF with just one click and crop instead of retyping the text character by character. A tipical use case is to copy any text from youtube videos, image formatted tutorials.
This tool copies text from images using the lightweight OCR engine [Tesseract.js](https://github.com/naptha/tesseract.js).
How to use it:
1. Click the icon, then select the area/image containing the text.
2. Wait until the tool to extract the text for you.
3. Extracted result will show in a text box. You can then click the copy button to load it into your Clipboard and Ctrl + V to paste it anywhere.
4. There is an option to translate the extracted text into your selected language.
5. You can define the ORC language and targeted translation languages on the options page. Основная информация о расширении
| Название |  ORC Text Snap ORC Text Snap |
| ID | cjcbfnbbhjipgbbncobdgdpphnlalife |
| Официальный URL | https://chromewebstore.google.com/detail/orc-text-snap/cjcbfnbbhjipgbbncobdgdpphnlalife |
| Описание | Extract text from images with Optical Character Recognition |
| Размер файла | 236 KB |
| Количество установок | 1,886 |
| Текущая Версия | 1.1 |
| Последнее Обновление | 2022-09-17 |
| Дата публикации | 2019-08-27 |
| Рейтинг | 2.00/5 Всего 5 оценок |
| Разработчик | Jofen |
| Электронная почта | [email protected] |
| Тип оплаты | free |
| Поддерживаемые языки | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"name": "ORC Text Snap",
"description": "Extract text from images with Optical Character Recognition",
"version": "1.1",
"manifest_version": 2,
"background": {
"scripts": [
"dist\/main.js",
"js\/background.js"
],
"persistent": false
},
"browser_action": {
"default_icon": {
"19": "images\/icon19.png",
"38": "images\/icon38.png"
},
"default_title": "Extract text from images"
},
"options_ui": {
"page": "html\/options.html",
"open_in_tab": false,
"chrome_style": true
},
"icons": {
"16": "images\/icon16.png",
"48": "images\/icon48.png",
"128": "images\/icon128.png"
},
"homepage_url": "https:\/\/github.com\/jofen-chrome-extensions\/orc-text-snap",
"web_accessible_resources": [
"html\/iframe\/*",
"images\/Jcrop.gif",
"images\/pixel.png",
"images\/close.png"
],
"commands": {
"take-screenshot": {
"suggested_key": {
"default": "Alt+S"
},
"description": "Take Screenshot"
}
},
"permissions": [
"storage",
"tabs",
"activeTab",
"clipboardWrite"
],
"content_scripts": [
{
"matches": [
"*:\/\/*\/*"
],
"js": [
"vendor\/jquery.js",
"js\/inject.js"
],
"css": [
"css\/inject.css"
],
"run_at": "document_start"
}
],
"content_security_policy": "script-src 'self' 'unsafe-eval' https:\/\/cdn.jsdelivr.net; object-src 'self'"
} | |











