ISBN Extractor
Automatically extract all ISBN from a webpage.
ISBN Extractor là gì?
ISBN Extractor là một tiện ích mở rộng Chrome được phát triển bởi Ray, và tính năng chính của nó là "Automatically extract all ISBN from a webpage.".
Ảnh Chụp Màn Hình của Tiện Ích Mở Rộng
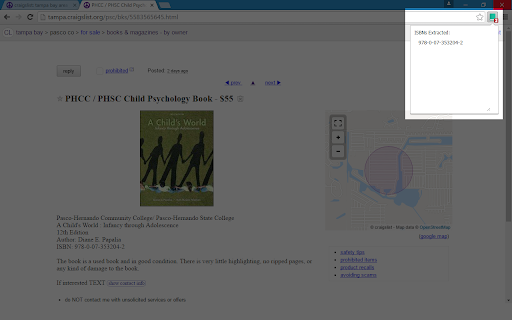
Tải xuống tệp CRX của tiện ích mở rộng ISBN Extractor
Tải xuống các tệp mở rộng ISBN Extractor dưới định dạng crx, cài đặt các tiện ích mở rộng Chrome bằng tay trong trình duyệt hoặc chia sẻ các tệp crx với bạn bè để dễ dàng cài đặt các tiện ích mở rộng Chrome.
Hướng Dẫn Sử Dụng Tiện Ích Mở Rộng
This is a simple extension that will extract all ISBN from any web page.
Extracts all 10 or 13 digit ISBNs (even if separated by spaces or -).
If you want to make the list comma separated or anything like that I recommend http://sortmylist.com/
**Update Version 1.1 **
Updated ISBN matching pattern.
ISBN scraping now is a bit cleaner
Updated to latest Google APIs
Fixed problem of not extracting after switching tabs Thông Tin Cơ Bản về Tiện Ích Mở Rộng
| Tên |  ISBN Extractor ISBN Extractor |
| ID | bjillcfelggegochlahahhlfcgfmddip |
| URL Chính Thức | https://chromewebstore.google.com/detail/isbn-extractor/bjillcfelggegochlahahhlfcgfmddip |
| Mô tả | Automatically extract all ISBN from a webpage. |
| Kích Thước Tệp | 535 KB |
| Số Lần Cài Đặt | 479 |
| Phiên Bản Hiện Tại | 1.1.2 |
| Cập Nhật Lần Cuối | 2022-04-23 |
| Ngày Phát Hành | 2016-06-21 |
| Đánh Giá | 4.75/5 Tổng số 4 Đánh Giá |
| Nhà Phát Triển | Ray |
| [email protected] | |
| Loại Thanh Toán | free |
| Ngôn Ngữ Được Hỗ Trợ | en-US |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"manifest_version": 2,
"name": "ISBN Extractor",
"offline_enabled": true,
"permissions": [
"webNavigation",
"chrome:\/\/favicon\/",
"https:\/\/*\/*",
"http:\/\/*\/*",
"tabs",
"storage"
],
"version": "1.1.2",
"content_security_policy": "script-src 'self' https:\/\/ssl.google-analytics.com; object-src 'self'",
"background": {
"scripts": [
"js\/background.js"
],
"persistent": true
},
"browser_action": {
"default_icon": "icons\/icon512.png",
"default_title": "ISBN Extractor!",
"default_popup": "src\/page_action\/page_action.html"
},
"content_scripts": [
{
"js": [
"js\/content.js"
],
"matches": [
"http:\/\/*\/*",
"https:\/\/*\/*",
"file:\/\/*"
],
"run_at": "document_end"
}
],
"description": "Automatically extract all ISBN from a webpage.",
"icons": {
"512": "icons\/icon512.png"
}
} | |











