Robots Exclusion Checker
Live URL checks against robots.txt, meta robots, x-robots-tag & canonical tags. Simple Red, Amber & Green status. An SEO Extension.
什么是Robots Exclusion Checker?
Robots Exclusion Checker是由https://www.samgipson.com开发的Chrome扩展程序,该扩展的主要功能是“Live URL checks against robots.txt, meta robots, x-robots-tag & canonical tags. Simple Red, Amber & Green status. An SEO Extension.”。
扩展截图


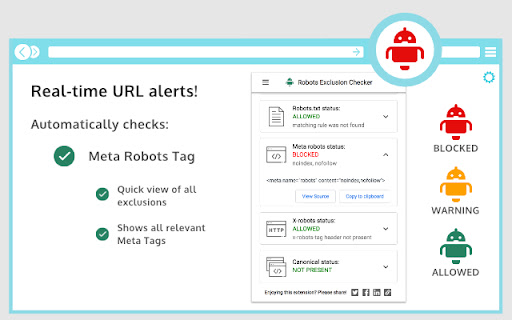


下载Robots Exclusion Checker扩展crx文件
下载Robots Exclusion Checker扩展crx格式的文件,手动将Chrome插件安装到浏览器中,也可以将crx文件分享给朋友,轻松安装Chrome插件。
扩展使用说明
Robots Exclusion Checker is designed to visually indicate whether any robots exclusions are preventing your page from being crawled or indexed by Search Engines.
## The extension reports on 5 elements:
1. Robots.txt
2. Meta Robots tag
3. X-robots-tag
4. Rel=Canonical
5. UGC, Sponsored and Nofollow attribute values
- Robots.txt
If a URL you are visiting is being affected by an "Allow” or “Disallow” within robots.txt, the extension will show you the specific rule within the extension, making it easy to copy or visit the live robots.txt. You will also be shown the full robots.txt with the specific rule highlighted (if applicable). Cool eh!
- Meta Robots Tag
Any Robots Meta tags that direct robots to “index", “noindex", “follow" or “nofollow" will flag the appropriate Red, Amber or Green icons. Directives that won’t affect Search Engine indexation, such as “nosnippet” or “noodp” will be shown but won’t be factored into the alerts. The extension makes it easy to view all directives, along with showing you any HTML meta robots tags in full that appear in the source code.
- X-robots-tag
Spotting any robots directives in the HTTP header has been a bit of a pain in the past but no longer with this extension. Any specific exclusions will be made very visible, as well as the full HTTP Header - with the specific exclusions highlighted too!
- Canonical Tags
Although the canonical tag doesn’t directly impact indexation, it can still impact how your URLs behave within SERPS (Search Engine Results Pages). If the page you are viewing is Allowed to bots but a Canonical mismatch has been detected (the current URL is different to the Canonical URL) then the extension will flag an Amber icon. Canonical information is collected on every page from within the HTML and HTTP header response.
- UGC, Sponsored and Nofollow
A new addition to the extension gives you the option to highlight any visible links that use a "nofollow", "ugc" or "sponsored" rel attribute value. You can control which links are highlighted and set your preferred colour for each. I’d you’d prefer this is disabled, you can switch off entirely.
## User-agents
Within settings, you can choose one of the following user-agents to simulate what each Search Engine has access to:
1. Googlebot
2. Googlebot news
3. Bing
4. Yahoo
## Benefits
This tool will be useful for anyone working in Search Engine Optimisation (SEO) or digital marketing, as it gives a clear visual indication if the page is being blocked by robots.txt (many existing extensions don’t flag this). Crawl or indexation issues have a direct bearing on how well your website performs in organic results, so this extension should be part of your SEO developer toolkit for Google Chrome. An alternative to some of the common robots.txt testers available online.
This extension is useful for:
- Faceted navigation review and optimisation (useful to see the robot control behind complex / stacked facets)
- Detecting crawl or indexation issues
- General SEO review and auditing within your browser
## Avoid the need for multiple SEO Extensions
Within the realm of robots and indexation, there is no better extension available. In fact, by installing Robots Exclusion Checker you will avoid having to run multiple extensions within Chrome that will slow down its functionality.
Similar plugins include:
NoFollow
https://chrome.google.com/webstore/detail/nofollow/dfogidghaigoomjdeacndafapdijmiid
Seerobots
https://chrome.google.com/webstore/detail/seerobots/hnljoiodjfgpnddiekagpbblnjedcnfp
NoIndex,NoFollow Meta Tag Checker
https://chrome.google.com/webstore/detail/noindexnofollow-meta-tag/aijcgkcgldkomeddnlpbhdelcpfamklm
CHANGELOG:
1.0.2: Fixed a bug preventing meta robots from updating after a URL update.
1.0.3: Various bug fixes, including better handling of URLs with encoded characters. Robots.txt expansion feature to allow the viewing of extra-long rules. Now JavaScript history.pushState() compatible.
1.0.4: Various upgrades. Canonical tag detection added (HTML and HTTP Header) with Amber icon alerts. Robots.txt is now shown in full, with the appropriate rule highlighted. X-robots-tag now highlighted within full HTTP header information. Various UX improvements, such as "Copy to Clipboard” and “View Source” links. Social share icons added.
1.0.5: Forces a background HTTP header call when the extension detects a URL change but no new HTTP header info - mainly for sites heavily dependant on JavaScript.
1.0.6: Fixed an issue with the hash part of the URL when doing a canonical check.
1.0.7: Forces a background body response call in addition to HTTP headers, to ensure a non-cached view of the URL for JavaScript heavy sites.
1.0.8: Fixed an error that occurred when multiple references to the same user-agent were detected within robots.txt file.
1.0.9: Fixed an issue with the canonical mismatch alert.
1.1.0: Various UI updates, including a JavaScript alert when the extension detects a URL change with no new HTTP request.
1.1.1: Added additional logic Meta robots user-agent rule conflicts.
1.1.2: Added a German language UI.
1.1.3: Added UGC, Sponsored and Nofollow link highlighting.
1.1.4: Switched off nofollow link highlighting by default on new installs and fixed a bug related to HTTP header canonical mismatches.
1.1.5: Bug fixes to improve robots.txt parser.
1.1.6: Extension now flags 404 errors in Red.
1.1.7: Not sending cookies when making a background request to fetch a page that was navigated to with pushstate.
1.1.8: Improvements to the handling of relative vs absolute canonical URLs and unencoded URL messaging.
Found a bug or want to make a suggestion? Please email extensions @ samgipson.com 扩展基本信息
| 名称 |  Robots Exclusion Checker Robots Exclusion Checker |
| ID | lnadekhdikcpjfnlhnbingbkhkfkddkl |
| 官方URL | https://chromewebstore.google.com/detail/robots-exclusion-checker/lnadekhdikcpjfnlhnbingbkhkfkddkl |
| 简介 | Live URL checks against robots.txt, meta robots, x-robots-tag & canonical tags. Simple Red, Amber & Green status. An SEO Extension. |
| 文件大小 | 170 KB |
| 安装次数 | 37,442 |
| 当前版本 | 1.1.8.1 |
| 更新时间 | 2022-05-12 |
| 上架时间 | 2020-04-02 |
| 评分 | 5.00/5 共27次评分 |
| 开发者 | https://www.samgipson.com |
| 电子邮箱 | [email protected] |
| 付费类型 | free |
| 帮助页面URL | https://www.samgipson.com/robots-exclusion-checker-chrome-extension/ |
| 隐私政策页面URL | https://www.samgipson.com/rec-privacy-policy |
| 支持的语言 | de,en,fr |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"manifest_version": 2,
"name": "__MSG_name__",
"description": "__MSG_description__",
"default_locale": "en",
"version": "1.1.8.1",
"icons": {
"128": "\/img\/logo_128.png",
"256": "\/img\/logo_256.png"
},
"browser_action": {
"default_icon": "\/img\/logo_grey_16.png",
"default_popup": "\/pages\/popup\/index.html"
},
"content_scripts": [
{
"matches": [
"http:\/\/*\/*",
"https:\/\/*\/*"
],
"all_frames": true,
"js": [
"\/js\/content_scripts\/link_highlighting.js"
]
}
],
"background": {
"scripts": [
"\/lib\/jquery.min.js",
"\/lib\/webx.js",
"\/lib\/url.min.js",
"\/js\/chrome_promise.js",
"\/lib\/webx_modules\/cache_manager.js",
"\/lib\/webx_modules\/ba_manager.js",
"\/js\/converters\/robots_main.js",
"\/js\/background\/modules\/page_info_manager.js",
"\/js\/background\/modules\/robot_validator.js",
"\/js\/background\/modules\/main_background_module.js",
"\/js\/background\/background.js"
],
"persistent": true
},
"permissions": [
"tabs",
"storage",
"unlimitedStorage",
"webRequest",
"http:\/\/*\/*",
"https:\/\/*\/*"
],
"web_accessible_resources": [
"\/*"
],
"content_security_policy": "script-src 'self' 'unsafe-eval' https:\/\/connect.facebook.net; object-src 'self'"
} | |











