Image Reader (OCR)
Easily get words out of an image with OCR engine!
什麼是Image Reader (OCR)?
Image Reader (OCR)是由Sevina開發的Chrome擴展程式,該擴展的主要功能是“Easily get words out of an image with OCR engine!”。
擴展截圖
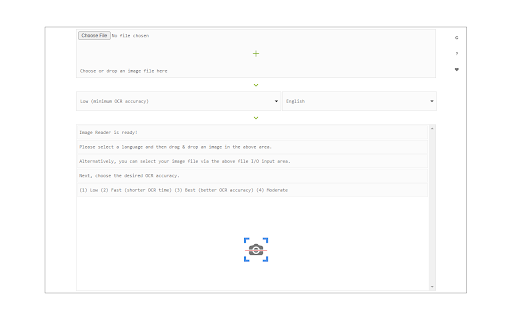

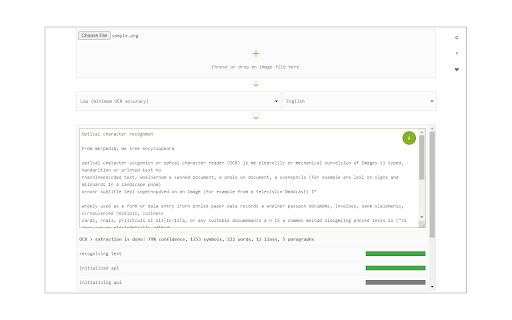
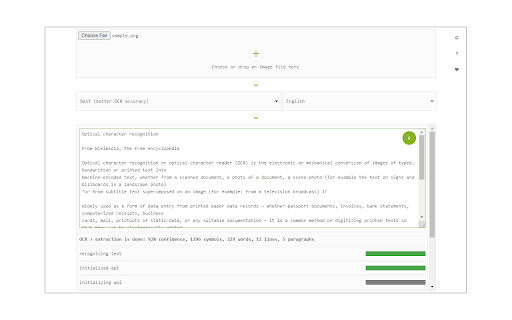
下載Image Reader (OCR)擴展crx文件
下載Image Reader (OCR)擴展crx格式的文件,手動將Chrome擴充功能安裝到瀏覽器中,也可以將crx文件分享給朋友,輕鬆安裝Chrome擴充功能。
擴展使用說明
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info.
To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English.
Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package.
To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html). 擴展基本資訊
| 名稱 |  Image Reader (OCR) Image Reader (OCR) |
| ID | cakcfocedphbadddjpalejbkhflfbhmf |
| 官方網址 | https://chromewebstore.google.com/detail/image-reader-ocr/cakcfocedphbadddjpalejbkhflfbhmf |
| 簡介 | Easily get words out of an image with OCR engine! |
| 檔案大小 | 7.51 MB |
| 安裝次數 | 31,444 |
| 目前版本 | 0.1.7 |
| 更新時間 | 2023-12-07 |
| 上架時間 | 2019-08-27 |
| 評分 | 3.85/5 共 20 次評分 |
| 開發者 | Sevina |
| 電子郵箱 | [email protected] |
| 付費類型 | free |
| 擴展官網 | https://mybrowseraddon.com/image-reader.html |
| 說明頁面URL | https://mybrowseraddon.com/image-reader.html |
| 隱私政策頁面URL | https://mybrowseraddon.com/privacy-policy/developer/sevina.html |
| 支援的語言 | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"version": "0.1.7",
"manifest_version": 3,
"offline_enabled": true,
"name": "Image Reader (OCR)",
"permissions": [
"storage",
"contextMenus"
],
"homepage_url": "https:\/\/mybrowseraddon.com\/image-reader.html",
"description": "Easily get words out of an image with OCR engine!",
"commands": {
"_execute_action": []
},
"background": {
"service_worker": "background.js"
},
"content_security_policy": {
"extension_pages": "script-src 'self' 'wasm-unsafe-eval'; object-src 'self'"
},
"action": {
"default_title": "Image Reader (OCR)",
"default_icon": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png"
}
},
"icons": {
"16": "data\/icons\/16.png",
"32": "data\/icons\/32.png",
"48": "data\/icons\/48.png",
"64": "data\/icons\/64.png",
"128": "data\/icons\/128.png"
}
} | |











