Listly - Web Scraping
A free easy-to-use web scraping tool. Extract Web data in a few clicks
什麼是Listly - Web Scraping?
Listly - Web Scraping是由https://listly.io開發的Chrome擴展程式,該擴展的主要功能是“A free easy-to-use web scraping tool. Extract Web data in a few clicks”。
擴展截圖

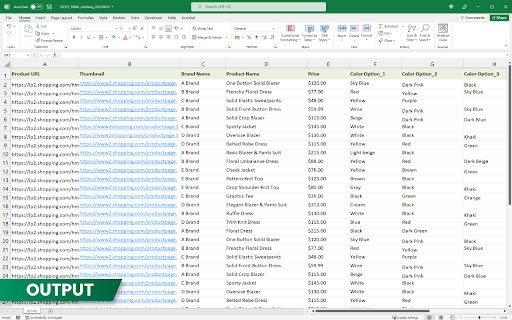
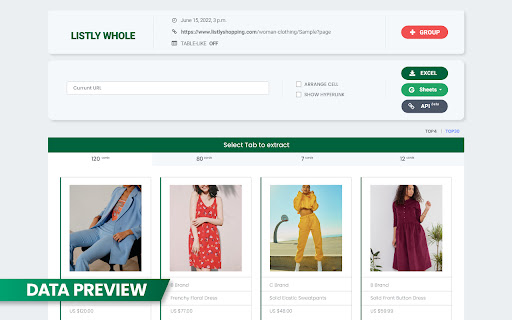
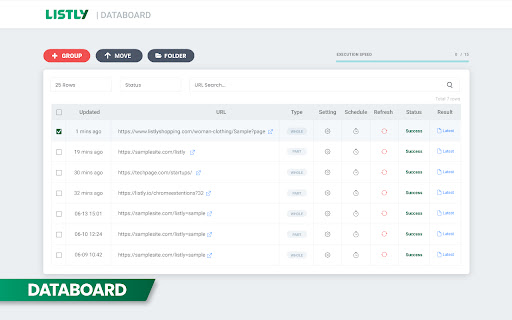

下載Listly - Web Scraping擴展crx文件
下載Listly - Web Scraping擴展crx格式的文件,手動將Chrome擴充功能安裝到瀏覽器中,也可以將crx文件分享給朋友,輕鬆安裝Chrome擴充功能。
擴展使用說明
Data collection doesn't need to be hard. We make it easy.
Convert any website to Excel in just a few clicks. Speed up your data collection and put your time and effort into what really matters to you.
With 180,000+ installs and more than 38.0M URL downloads globally, Listly is the easiest tool to use and the preferred web scraping service among marketers and real estate agents who want to get their job done faster.
See more features at www.listly.io.
Listly use cases
• Look for suitable job candidates as a recruiter
• Complete prospecting workflows as a sales representative
• Collect product and pricing information from eCommerce websites as a marketer
• Gather sports data to predict the outcome of sports games as a sports statistician
• Generate new leads for companies and freelancers
• Analyze social media posts, comments, likes, etc.
• Track real estate prices and listing information
• Identify potential competitors and monitor markets
• Scrape movie reviews and ratings
• Crawl various search engine results
Listly’s core features
• Export data to Excel or CSV/JSON
• Integrate with Google Sheets
• Schedule a daily extraction
• Receive e-mail notifications
• Integrate with an API for developers (Beta)
• Export multiple pages into an Excel spreadsheet
• Upload .html files via Fileboard
• Automate repetitive mouse or keyboard clicks to load more data
• Auto-Click to load more data
• Auto-Scroll to load more data
• Auto-Save while scrolling
• Add a custom proxy server to change IP address and avoid getting blocked
• Adjust the scraping speed to avoid getting blocked while scraping websites
• Automatically detect and extract iFrame elements
• Extract hyperlinks in content referring to web pages within a website 擴展基本資訊
| 名稱 |  Listly - Web Scraping Listly - Web Scraping |
| ID | ihljmnfgkkmoikgkdkjejbkpdpbmcgeh |
| 官方網址 | https://chromewebstore.google.com/detail/listly-web-scraping/ihljmnfgkkmoikgkdkjejbkpdpbmcgeh |
| 簡介 | A free easy-to-use web scraping tool. Extract Web data in a few clicks |
| 檔案大小 | 1.03 MB |
| 安裝次數 | 117,491 |
| 目前版本 | 0.5.1 |
| 更新時間 | 2023-12-15 |
| 上架時間 | 2020-05-06 |
| 評分 | 4.59/5 共 254 次評分 |
| 開發者 | https://listly.io |
| 電子郵箱 | [email protected] |
| 付費類型 | free |
| 擴展官網 | https://listly.io |
| 說明頁面URL | https://listly.io/faq |
| 隱私政策頁面URL | https://www.listly.io/privacy |
| 支援的語言 | en,ko |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"name": "__MSG_appName__",
"short_name": "Listly",
"version": "0.5.1",
"manifest_version": 3,
"description": "__MSG_appDesc__",
"homepage_url": "https:\/\/www.listly.io",
"icons": {
"16": "img\/icon16.png",
"32": "img\/icon32.png",
"48": "img\/icon48.png",
"128": "img\/icon128.png"
},
"default_locale": "en",
"background": {
"service_worker": "background.js"
},
"action": {
"default_icon": {
"16": "img\/icon16.png",
"32": "img\/icon32.png"
},
"default_title": "__MSG_appTitle__",
"default_popup": "html\/popup.html"
},
"permissions": [
"activeTab",
"tabs",
"scripting",
"storage",
"cookies",
"unlimitedStorage"
],
"host_permissions": [
"file:\/\/\/*.html",
"http:\/\/*\/*",
"https:\/\/*\/*"
],
"content_security_policy": {
"extension_pages": "script-src 'self'; object-src 'self'"
},
"content_scripts": [
{
"matches": [
"file:\/\/\/*.html",
"http:\/\/*\/*",
"https:\/\/*\/*"
],
"css": [
"css\/content_script.css"
],
"js": [
"js\/lib\/jquery\/jquery-3.7.1.min.js",
"js\/lib\/selector\/optimal-select.min.js",
"js\/lib\/selector\/finder.js",
"js\/lib\/selector\/css-selector-generator.js",
"js\/data_selector.js",
"js\/content\/selector\/geometry.js",
"js\/content\/selector\/txtimg_nodes.js",
"js\/content\/selector\/init_listlypick.js",
"js\/content\/selector\/init_listlymultitab.js",
"js\/content_script.js",
"js\/process_all_tabs.js",
"js\/process_part_tabs.js"
],
"run_at": "document_end",
"match_about_blank": true,
"all_frames": true
}
],
"web_accessible_resources": [
{
"resources": [
"html\/loading\/iframe.html",
"html\/sidepanel\/iframe.html",
"html\/sidepanel\/parts_iframe.html"
],
"matches": [
" | |











